


Supermicro NVIDIA Blackwell: eficiência e densidade redefinidas na era da IA generativa No momento em que a inteligência artificial generativa atinge escalas de trilhões de parâmetros, a infraestrutura de data centers enfrenta o desafio de equilibrar desempenho computacional extremo com eficiência energética e densidade operacional. Nesse cenário, a Supermicro redefine os limites do design de sistemas com suas soluções baseadas na NVIDIA Blackwell, introduzindo uma nova geração de SuperClusters otimizados para refrigeração líquida direta (DLC). O lançamento representa mais que uma atualização tecnológica: trata-se de uma mudança estrutural na forma como a computação acelerada será implantada nos próximos anos. Com os novos sistemas HGX B200 8-GPU, as plataformas GB200 Grace Blackwell e o impressionante GB200 NVL72, a Supermicro eleva o conceito de densidade computacional e eficiência térmica a níveis inéditos no setor de IA e HPC. O desafio estratégico da IA em escala de trilhões de parâmetros As arquiteturas modernas de IA generativa exigem quantidades massivas de poder de cálculo, memória de alta largura de banda e interconexões de baixa latência. Modelos com trilhões de parâmetros impõem pressões inéditas sobre a infraestrutura física, especialmente em aspectos como dissipação térmica, densidade de GPU por rack e consumo energético global. Empresas que operam em larga escala enfrentam o dilema de expandir poder computacional sem comprometer a sustentabilidade operacional. A abordagem tradicional de resfriamento a ar já não é suficiente para manter estabilidade térmica em sistemas com centenas de GPUs de alto TDP. É nesse contexto que a Supermicro NVIDIA Blackwell se destaca, integrando arquitetura de hardware de última geração com soluções térmicas otimizadas para o futuro dos data centers. As consequências da inação: limites físicos e custos exponenciais Ignorar a necessidade de eficiência térmica e energética significa enfrentar aumentos vertiginosos em custos operacionais e restrições físicas de densidade. Data centers baseados em ar condicionado tradicional atingem rapidamente seus limites quando tentam hospedar sistemas de IA de múltiplos petaflops por rack. A consequência é dupla: desperdício de energia e subutilização de espaço crítico. Sem soluções de refrigeração avançadas, o desempenho das GPUs é limitado por thermal throttling, e o custo por watt de computação útil cresce de forma não linear. A abordagem da Supermicro — com refrigeração líquida direta e design vertical de distribuição de fluido — rompe essa barreira, oferecendo um caminho sustentável para expansão de cargas de IA em escala exascale. Fundamentos técnicos das soluções Supermicro NVIDIA Blackwell Arquitetura HGX B200: computação concentrada em eficiência No coração do novo SuperCluster está o sistema NVIDIA HGX B200 8-GPU, projetado para maximizar densidade e eficiência térmica. A Supermicro introduziu um design de rack escalável com manifolds verticais de distribuição de refrigerante (CDMs), que permitem abrigar mais nós de computação por rack, sem comprometer estabilidade térmica ou segurança operacional. As melhorias incluem cold plates redesenhadas e um sistema avançado de mangueiras que otimiza a circulação do líquido de resfriamento. Para implantações de larga escala, a Supermicro oferece ainda uma opção de unidade de distribuição de refrigeração (CDU) integrada à fileira, reduzindo complexidade e perdas térmicas. A eficiência é tamanha que mesmo data centers baseados em ar podem adotar chassis especialmente desenvolvidos para o novo HGX B200. Processadores e integração com rede de alta performance O sistema suporta duas CPUs Intel Xeon 6 (500W) ou AMD EPYC 9005, ambas com suporte a DDR5 MRDIMMs a 8800 MT/s, garantindo largura de banda de memória suficiente para alimentar as oito GPUs Blackwell, cada uma com TDP de até 1000W. A arquitetura é complementada por uma relação 1:1 GPU–NIC, viabilizando interconexão direta entre cada GPU e uma interface de rede NVIDIA BlueField-3 SuperNIC ou ConnectX-7. Essa topologia assegura latência mínima e escalabilidade linear em ambientes distribuídos, permitindo que o cluster opere como uma malha coesa de aceleração de IA. Além disso, cada sistema incorpora duas unidades de processamento de dados (DPUs) BlueField-3 dedicadas ao fluxo de dados com armazenamento de alto desempenho, aliviando a carga sobre as CPUs principais. Soluções com NVIDIA GB200 Grace Blackwell Superchips Convergência entre HPC e IA A linha GB200 Grace Blackwell da Supermicro representa o próximo salto na integração entre CPU e GPU, unificando o poder computacional do NVIDIA Grace com o processamento paralelo do Blackwell em um único superchip. Essa arquitetura suporta o novo NVL4 Superchip e o monumental NVL72, abrindo caminho para o conceito de exascale computing em um único rack. No NVL4, quatro GPUs Blackwell são interligadas via NVLink e acopladas a dois CPUs Grace por meio do protocolo NVLink-C2C, formando um domínio computacional de baixa latência e altíssima eficiência de memória. O resultado é um salto de até 2x no desempenho para cargas como computação científica, redes neurais gráficas e inferência de IA, em comparação à geração anterior Hopper. GB200 NVL72: supercomputação exascale em um único rack O Supermicro GB200 NVL72 SuperCluster consolida 72 GPUs Blackwell e 36 CPUs Grace em um único sistema coeso, conectados por NVLink de quinta geração e NVLink Switch. Essa topologia transforma o cluster em um “único superprocessador”, com um pool unificado de memória HBM3e e largura de banda total de comunicação de 130 TB/s. O resultado é uma arquitetura de computação que elimina gargalos de comunicação e oferece desempenho contínuo para treinamentos e inferências de larga escala. O sistema é complementado pelo SuperCloud Composer (SCC), software de orquestração e monitoramento que permite gerenciar de forma centralizada toda a infraestrutura de refrigeração líquida e desempenho térmico do data center. Supermicro H200 NVL: equilíbrio entre potência e flexibilidade Nem todas as cargas de trabalho requerem densidade exascale. Para organizações que buscam flexibilidade em implementações menores, a Supermicro oferece sistemas PCIe 5U com NVIDIA H200 NVL. Essas soluções são ideais para racks corporativos de energia moderada, mantendo compatibilidade com resfriamento a ar e múltiplas configurações de GPU. Com até quatro GPUs interligadas por NVLink, o H200 NVL oferece 1,5x mais memória e 1,2x mais largura de banda em comparação ao modelo anterior, acelerando o fine-tuning de LLMs em poucas horas e proporcionando até 1,7x mais desempenho em inferência. Além disso, inclui assinatura de cinco anos

Introdução A Supermicro, reconhecida mundialmente como um dos principais fabricantes de soluções completas de TI para inteligência artificial, nuvem e data centers, anunciou um movimento estratégico de grande escala: a construção de seu terceiro campus em Silicon Valley. Mais do que uma simples expansão física, o projeto representa uma reconfiguração do ecossistema de inovação dos Estados Unidos, com implicações diretas na economia local, na eficiência energética e no avanço de tecnologias críticas para o futuro da infraestrutura digital global. Em um cenário onde o crescimento de aplicações baseadas em IA exige infraestruturas cada vez mais potentes e sustentáveis, a iniciativa da Supermicro responde a uma necessidade premente: repensar como os data centers são projetados, resfriados e operados. O novo campus, que deverá atingir quase 3 milhões de pés quadrados, simboliza a convergência entre expansão industrial, inovação tecnológica e compromisso ambiental — pilares que sustentam a competitividade no mercado global de TI. O artigo a seguir analisa em profundidade o impacto estratégico dessa expansão, seus fundamentos tecnológicos, a transformação da cadeia produtiva e os desdobramentos para o mercado de data centers líquidos e computação de alta performance (HPC). O problema estratégico: infraestrutura em transformação O crescimento exponencial da IA tem pressionado a infraestrutura tradicional de TI. A densidade computacional exigida por modelos generativos e inferência em larga escala ultrapassa os limites de refrigeração de data centers convencionais. Sistemas baseados apenas em ar, outrora suficientes, agora enfrentam gargalos térmicos, energéticos e de densidade. Empresas globais procuram alternativas que equilibrem desempenho, eficiência energética e sustentabilidade. Nesse contexto, a refrigeração líquida surge não apenas como tendência, mas como imperativo técnico e econômico. Entretanto, sua adoção demanda ecossistemas integrados — desde design de servidores até integração de energia e rede — o que limita a capacidade de resposta de fabricantes fragmentados. Para a Supermicro, a lacuna entre demanda e capacidade instalada representava um desafio estratégico: como manter sua liderança tecnológica e atender à nova geração de “fábricas de IA” sem comprometer agilidade, qualidade ou sustentabilidade? Consequências da inação Ignorar a transição para tecnologias líquidas e infraestruturas otimizadas para IA teria custos substanciais. Data centers baseados exclusivamente em ar tendem a apresentar elevação constante de consumo elétrico, degradação de componentes e limitações físicas que comprometem a expansão. Em um mercado onde o tempo de implantação (TTD) e o tempo de entrada em operação (TTO) determinam vantagem competitiva, atrasos de semanas podem significar milhões em perdas. Além disso, a ausência de capacidade local de produção — especialmente nos EUA — comprometeria a autonomia industrial frente a cadeias de suprimentos asiáticas e à crescente demanda doméstica por servidores otimizados para IA e HPC. A inação implicaria perda de mercado e dependência tecnológica. Fundamentos da solução: expansão e integração industrial O plano de expansão anunciado pela Supermicro vai muito além da construção física de prédios. Ele simboliza a consolidação de uma arquitetura industrial integrada, que une design, fabricação e testes de soluções completas sob o conceito de Total IT Solutions. O novo campus de Silicon Valley, que inicia com um edifício de mais de 300 mil pés quadrados, permitirá à empresa aumentar sua produção para até 5.000 racks com refrigeração a ar ou 2.000 racks com refrigeração líquida por mês. Essa capacidade de produção massiva é o coração de uma estratégia de escala e resposta rápida às demandas globais por infraestrutura de IA. A abordagem Building Block Solutions® da Supermicro — um ecossistema modular de componentes reutilizáveis que inclui placas-mãe, sistemas de energia, chassis e soluções de resfriamento — garante flexibilidade para adaptar servidores a workloads diversos, desde IA generativa até HPC e nuvem corporativa. O foco em refrigeração líquida destaca um compromisso técnico com eficiência e sustentabilidade. A empresa estima que cerca de 30% dos novos data centers adotarão esse modelo, reduzindo significativamente o consumo energético e a emissão de carbono associada à operação de grandes clusters computacionais. Implementação estratégica: ecossistema e governança tecnológica A execução desse projeto de expansão envolve coordenação entre múltiplos atores: governo municipal, fornecedores de energia e parceiros de tecnologia. O apoio do prefeito de San Jose e a colaboração com a PG&E, responsável por energia e infraestrutura, demonstram uma sinergia público-privada rara, centrada em crescimento sustentável e inovação de base local. Segundo a própria Supermicro, a nova planta criará centenas de empregos de alta qualificação, incluindo engenheiros, técnicos e profissionais corporativos. Esse investimento em capital humano é tão estratégico quanto o investimento em infraestrutura: a empresa reforça o conceito de “Made in America” como sinônimo de excelência tecnológica e soberania industrial. Do ponto de vista de governança, a Supermicro mantém o controle integral sobre design, fabricação e testes — um modelo verticalizado que minimiza riscos de fornecimento e garante consistência de qualidade. A expansão também integra princípios de Green Computing, alinhando-se às metas de eficiência energética e redução de emissões impostas por regulações ambientais e por clientes corporativos globais. Melhores práticas avançadas: inovação sustentável e tempo de implantação Entre as práticas mais relevantes da Supermicro destacam-se a otimização de Time-to-Deployment (TTD) e Time-to-Online (TTO). Ao reduzir o intervalo entre fabricação e operação efetiva, a empresa melhora o ciclo de entrega e acelera o retorno sobre investimento para seus clientes. Isso é particularmente crítico em projetos de IA, onde a demanda por capacidade de processamento evolui rapidamente. A padronização modular da linha Building Block Solutions® também promove interoperabilidade entre gerações de hardware, permitindo atualizações graduais sem substituição total da infraestrutura. Essa abordagem reduz o custo total de propriedade (TCO) e prolonga o ciclo de vida operacional de data centers. Por fim, o investimento em refrigeração líquida demonstra uma visão de longo prazo. O resfriamento direto por líquido, ao reduzir o consumo de energia elétrica em comparação com sistemas de ar condicionado, cria um efeito cascata de eficiência — menores custos operacionais, menor necessidade de manutenção e melhor densidade computacional por rack. Medição de sucesso: impacto econômico e tecnológico A eficácia dessa expansão pode ser avaliada por métricas objetivas e intangíveis. Entre os indicadores tangíveis estão o número de racks entregues mensalmente, a capacidade

Introdução A corrida por poder computacional nunca foi tão intensa quanto em 2025. À medida que o avanço da inteligência artificial redefine indústrias inteiras, os chips que sustentam esse ecossistema tornam-se ativos estratégicos de valor incomensurável. O mais recente capítulo dessa disputa foi escrito pela AMD e pela OpenAI, que anunciaram um acordo bilionário para fornecimento de aceleradores de IA com potencial para reconfigurar o equilíbrio de poder no mercado dominado pela Nvidia. O compromisso prevê que a OpenAI adquira até 6 gigawatts em aceleradores da AMD nos próximos cinco anos, com o primeiro lote baseado na GPU Instinct MI450, prevista para o segundo semestre de 2026. Mais do que uma transação comercial, esse acordo reflete a transformação estrutural da infraestrutura de IA — onde a inferência passa a ser o motor econômico central, e a dependência tecnológica torna-se uma vulnerabilidade estratégica. Empresas que não compreenderem as implicações dessa aliança correm o risco de perder competitividade em um mercado em que o controle sobre a capacidade de processamento equivale a dominar o próprio ciclo de inovação. Este artigo aprofunda o contexto, as motivações e as implicações técnicas e empresariais dessa parceria. O problema estratégico: escassez e dependência tecnológica Nos últimos anos, o mercado global de IA enfrentou um problema recorrente: a escassez crônica de GPUs capazes de atender à demanda crescente por treinamento e inferência de modelos de larga escala. A Nvidia, líder incontestável no segmento, viu suas receitas crescerem quase sete vezes em quatro anos, alcançando US$ 130,5 bilhões em 2025. Esse domínio, porém, criou uma dependência estrutural que limita a expansão de empresas emergentes de IA, incluindo a própria OpenAI. Do ponto de vista estratégico, depender de um único fornecedor representa um risco de concentração inaceitável. A Nvidia, mesmo com sua capacidade industrial sem precedentes, não consegue atender à demanda insaciável por aceleradores de IA, criando gargalos que comprometem cronogramas e aumentam custos de operação. Esse cenário levou a OpenAI a diversificar suas fontes de hardware — primeiro com Broadcom e agora com AMD — em busca de resiliência e autonomia tecnológica. Além disso, o foco crescente na inferência de IA — ou seja, na execução prática de modelos em ambiente produtivo — exige arquiteturas otimizadas para eficiência energética e densidade computacional. Essa transição impõe novas exigências aos fornecedores de chips e redefine o que significa “liderança” em aceleração de IA. Consequências da inação Ignorar a necessidade de diversificação de hardware e de investimentos em capacidade de inferência é uma aposta perigosa. A falta de alternativas à Nvidia não apenas cria vulnerabilidade operacional, mas também limita o poder de negociação das empresas consumidoras de chips, concentrando inovação e margem de lucro em um único polo. Para provedores de nuvem, como Microsoft, Google e Meta, a ausência de fornecedores alternativos significa custos crescentes e menor flexibilidade arquitetônica em seus data centers. Para a OpenAI, o impacto é ainda mais direto: sem acesso contínuo a chips de alto desempenho, sua capacidade de oferecer inferência comercial em escala — base de sua receita futura — ficaria comprometida. A consequência estratégica seria dupla: estagnação tecnológica e perda de vantagem competitiva. Em mercados guiados por ciclos rápidos de aprendizado e adaptação, atrasos de meses podem significar anos de desvantagem acumulada. Fundamentos da solução: o papel do MI450 No centro do acordo entre AMD e OpenAI está o Instinct MI450, sucessor da série MI300X, projetado para competir diretamente com os superchips Vera Rubin da Nvidia. A arquitetura do MI450 incorpora avanços em memória de alta largura de banda (HBM4) e densidade de processamento, oferecendo até 432 GB de memória e desempenho superior a 40 PFLOPs em FP4. Essas especificações representam mais do que um salto técnico — são a base de uma nova geração de infraestrutura de inferência, projetada para maximizar throughput, reduzir latência e otimizar consumo energético. Comparado ao Vera Rubin, com 288 GB de HBM4 e 50 PFLOPs, o MI450 oferece uma proposta de equilíbrio entre eficiência, escalabilidade e custo total de propriedade (TCO). Do ponto de vista empresarial, o MI450 posiciona a AMD como uma alternativa concreta em um mercado até então monopolizado. Essa pluralidade de oferta pode catalisar um ciclo virtuoso de inovação, reduzindo preços e aumentando o acesso a tecnologias de ponta para novas empresas e centros de pesquisa. Implementação estratégica: arquitetura e impacto empresarial Implementar o MI450 em escala requer mais do que integração de hardware — envolve planejamento arquitetônico e reengenharia de workloads. As cargas de trabalho de inferência demandam otimização de pipelines de dados, suporte a formatos quantizados como FP4 e integração com frameworks como PyTorch e TensorRT. A AMD, historicamente atrás da Nvidia nesse ecossistema, vem investindo em camadas de software e bibliotecas abertas que reduzam essa distância. Para a OpenAI, a adoção estratégica da linha Instinct representa um movimento de diversificação inteligente. Ao construir infraestrutura com múltiplos fornecedores, a empresa reduz o risco de interrupções de fornecimento e aumenta a resiliência operacional. Além disso, cria condições para testar arquiteturas híbridas, combinando chips AMD e Nvidia de acordo com o perfil de cada workload. Essa abordagem também tem implicações financeiras. A troca por warrants equivalentes a 10% das ações da AMD consolida uma relação de longo prazo, alavancando valor para ambas as partes: a AMD garante demanda previsível e legitimidade no mercado de IA, enquanto a OpenAI obtém prioridade em fornecimento e acesso antecipado a novas gerações de chips. Melhores práticas avançadas e desafios técnicos Embora a adoção do MI450 represente uma oportunidade, sua integração não está isenta de desafios. O principal deles é o ecossistema de software. O domínio da Nvidia não se deve apenas à superioridade de hardware, mas à maturidade do CUDA e de seu stack completo de ferramentas, otimizadas para cada geração de GPU. A AMD precisa consolidar sua plataforma ROCm como um ambiente robusto, compatível e eficiente para execução de cargas de inferência de larga escala. Para isso, empresas como a OpenAI tornam-se parceiras críticas na validação de performance, escalabilidade e interoperabilidade. Cada avanço obtido nesse contexto representa um

O Futuro da IA na Ciência: Impulsionando Descobertas e Inovação Estratégica Organizações em todo o mundo estão intensificando iniciativas para aproveitar os avanços da inteligência artificial (IA), inclusive na comunidade científica. A IA não é mais apenas uma ferramenta de automação; ela se tornou um catalisador estratégico capaz de transformar como pesquisadores abordam problemas complexos, otimizam processos e exploram novas fronteiras do conhecimento. Contextualização Estratégica e Desafios Críticos A revolução da IA generativa, iniciada com o ChatGPT em 2022, mudou fundamentalmente a percepção de capacidade computacional aplicada à ciência. O entusiasmo inicial sobre modelos de linguagem de grande porte (LLMs) levantou a hipótese de que sistemas massivos de IA poderiam, eventualmente, responder questões científicas não triviais. Organizações como o Consórcio Trillion Parameter (TPC) propuseram metas ambiciosas, incluindo a criação de modelos de fronteira abertos e infraestrutura de dados compartilhada. No entanto, surgiram desafios críticos. O chamado “muro de escalonamento” demonstrou que simplesmente aumentar o número de parâmetros de um LLM não garante retorno proporcional em desempenho científico. Além disso, o suprimento limitado de dados de treinamento, gargalos de arquitetura de GPU e o alto custo de treinamento tornam a escalabilidade prática extremamente complexa. Consequências da Inação ou Implementação Inadequada Ignorar a integração da IA na pesquisa científica pode resultar em atrasos significativos em inovação e competitividade. Pesquisadores que não adotarem ferramentas de IA enfrentam maior tempo para experimentação, maior risco de erros humanos e menor capacidade de lidar com volumes massivos de dados científicos. Além disso, a falta de infraestrutura compartilhada limita a colaboração interinstitucional, impedindo avanços estratégicos em áreas críticas como modelagem climática, descoberta de medicamentos e ciência de materiais. Fundamentos da Solução: Modelos de IA e Raciocínio Científico O avanço científico orientado pela IA depende de fundamentos técnicos sólidos. Modelos de raciocínio, por exemplo, são projetados para executar tarefas cognitivas complexas: criar hipóteses, planejar e executar experimentos e analisar resultados. Diferente dos LLMs tradicionais, eles podem integrar dados experimentais em tempo real, aprendendo padrões e inferindo insights científicos que aceleram ciclos de pesquisa. Além disso, a criação de um modelo de fronteira aberto pelo TPC permite que toda a comunidade científica contribua e utilize uma base comum de dados e algoritmos. Essa abordagem não apenas democratiza o acesso à tecnologia, mas também garante maior transparência, auditabilidade e validação científica em experimentos de larga escala. Arquitetura e Infraestrutura Para suportar esses modelos, é essencial uma infraestrutura de dados e computação compartilhada. Servidores de alto desempenho, clusters de GPUs, armazenamento de alta velocidade e ferramentas de middleware são integrados para permitir experimentos contínuos e escaláveis. A interoperabilidade com laboratórios, sensores e instrumentos é crucial, garantindo que os modelos possam consumir dados em tempo real e gerar feedback acionável de forma eficiente. Implementação Estratégica A implementação bem-sucedida de IA na ciência exige abordagem metodológica cuidadosa. Primeiramente, dados científicos devem ser curados e padronizados. Em seguida, modelos de raciocínio precisam ser treinados e ajustados para domínios específicos. Finalmente, sistemas de IA de ponta são testados e validados em cenários de pesquisa real, com monitoramento contínuo de desempenho e métricas de sucesso. Considerações Críticas É fundamental avaliar trade-offs entre escala de modelo, custo computacional e precisão científica. Modelos maiores nem sempre garantem melhores resultados, e alucinações de IA podem comprometer conclusões. Estratégias de mitigação incluem validação cruzada com dados experimentais, pipelines de revisão por pares automatizados e auditoria contínua de resultados gerados por IA. Melhores Práticas Avançadas Cientistas que adotam IA devem seguir práticas avançadas de integração tecnológica. Isso inclui: uso de modelos híbridos que combinam raciocínio simbólico com aprendizado profundo; integração de sistemas de IA com workflows laboratoriais existentes; e utilização de pipelines de dados replicáveis e auditáveis. A ênfase está sempre em garantir que a IA amplifique, e não substitua, o raciocínio humano crítico. Medição de Sucesso O sucesso da IA na ciência deve ser medido por métricas qualitativas e quantitativas, incluindo tempo de descoberta reduzido, aumento da reprodutibilidade experimental, precisão na modelagem preditiva e capacidade de gerar novas hipóteses testáveis. Indicadores de adoção, colaboração interinstitucional e impacto científico também são essenciais para avaliar retorno estratégico. Conclusão A IA não é a solução mágica para todos os desafios científicos, mas representa uma alavanca poderosa para acelerar a pesquisa e inovação. Organizações que implementarem modelos de raciocínio, infraestrutura compartilhada e sistemas de fronteira abertos estarão melhor posicionadas para transformar dados em descobertas significativas. Embora a inteligência artificial geral ainda seja uma meta distante, o uso estratégico de IA permite avanços substanciais em eficiência, precisão e inovação científica. O futuro da pesquisa científica será definido por como a comunidade científica integra tecnologia, criatividade e colaboração para enfrentar os desafios mais complexos do conhecimento humano. Próximos passos incluem o investimento em treinamento de modelos de raciocínio específicos de domínio, integração de infraestrutura de dados compartilhada e desenvolvimento de sistemas de avaliação robustos, garantindo que a IA impulsione de forma responsável e estratégica a evolução da ciência.

Mercado global de HPC e IA: crescimento, números e tendências estratégicas O mercado de HPC (High Performance Computing) e Inteligência Artificial (IA) vive uma transformação sem precedentes, impulsionada pelo crescimento acelerado das cargas de trabalho de IA e pela crescente interdependência entre ciência de dados, simulação científica e inovação empresarial. Em 2024, segundo dados da Hyperion Research e da Intersect360, o setor atingiu cerca de US$ 60 bilhões, estabelecendo novos patamares de investimento em infraestrutura tecnológica crítica. Introdução: o papel estratégico do HPC e da IA A HPC, tradicionalmente associada a supercomputadores em laboratórios científicos e centros de pesquisa, passou a ter um papel central no avanço da IA generativa e empresarial. A convergência desses dois campos cria não apenas oportunidades técnicas, mas também dilemas estratégicos para organizações que precisam equilibrar investimentos em infraestrutura, governança de dados e competitividade global. Ignorar ou adotar tardiamente soluções em HPC e IA implica riscos claros: perda de produtividade em pesquisa, atraso em inovação industrial e desvantagem competitiva em setores emergentes como energia, farmacêutico e manufatura avançada. Assim, compreender os números e dinâmicas de mercado é mais do que um exercício estatístico – é uma bússola para decisões estratégicas de investimento. Neste artigo, exploramos em profundidade os dados de mercado divulgados por Hyperion Research e Intersect360, analisamos os principais fornecedores, tendências como exascale e IA soberana, e avaliamos implicações estratégicas para empresas e instituições. Problema estratégico: a pressão por infraestrutura escalável A principal tensão que organizações enfrentam hoje é o dilema entre infraestrutura local e soluções em nuvem. De acordo com a Hyperion, servidores locais representaram 42% dos gastos globais em 2024 (US$ 25 bilhões), enquanto a nuvem respondeu por apenas 15% (US$ 9 bilhões). Apesar do discurso recorrente de migração para nuvem, o crescimento mais acelerado ocorreu no modelo local, que registrou aumento anual de 23,4% – o maior em mais de duas décadas. Essa pressão por infraestrutura escalável não se limita a volumes de dados crescentes, mas envolve também requisitos de latência, soberania digital e otimização de custos em longo prazo. A nuvem oferece elasticidade, mas o controle e a previsibilidade de sistemas locais se mostram decisivos em setores que lidam com cargas críticas como simulação científica, energia e defesa. Consequências da inação: riscos competitivos e estratégicos Adiar investimentos em HPC e IA significa expor-se a riscos significativos. Empresas que não modernizam suas infraestruturas enfrentam gargalos computacionais que limitam desde a modelagem de novos fármacos até a engenharia avançada de materiais. Governos que atrasam iniciativas de HPC soberano arriscam perder autonomia em pesquisa científica e segurança nacional. Além disso, há o custo da oportunidade perdida: enquanto concorrentes aceleram pesquisas e desenvolvem produtos baseados em simulações complexas ou modelos generativos, organizações defasadas ficam presas a ciclos de inovação mais longos e caros. Fundamentos da solução: arquitetura do mercado global A arquitetura do mercado de HPC e IA pode ser compreendida pela segmentação feita por empresas de pesquisa como Hyperion e Intersect360. Em 2024, os componentes principais foram servidores locais (42%), serviços (21%), armazenamento (17%), nuvem (15%) e software (5%). Essa divisão revela que, apesar do discurso sobre cloud-first, a base tecnológica crítica continua fundamentada em infraestruturas locais robustas. Outro aspecto fundamental é a estratificação do mercado por classes de sistemas. A Hyperion reporta que sistemas de grande porte (US$ 1 milhão a US$ 10 milhões) somaram mais de US$ 7 bilhões, supercomputadores entre US$ 10 e 150 milhões movimentaram US$ 6,9 bilhões, e sistemas de nível básico (menos de US$ 250 mil) atingiram US$ 6,2 bilhões. Esse desenho confirma que tanto a pesquisa de ponta quanto a adoção ampla em empresas menores contribuem para o dinamismo do setor. Implementação estratégica: local, nuvem e híbrido Os dados mostram que organizações não precisam optar exclusivamente entre local e nuvem. A realidade estratégica é híbrida. Enquanto a nuvem suporta elasticidade para cargas sazonais e prototipagem rápida, servidores locais garantem controle, desempenho previsível e conformidade regulatória. A Intersect360 destaca que os servidores HPC-AI e Enterprise AI locais (excluindo hiperescala) representaram US$ 19,2 bilhões em 2024, com crescimento de 36,8%. Esse salto foi impulsionado por atualizações massivas para GPUs e pela demanda empresarial em múltiplos setores. Empresas que estruturam arquiteturas híbridas têm maior resiliência e flexibilidade para capturar esses ganhos. Melhores práticas avançadas: otimizando investimentos Modernização contínua com GPUs e aceleradores A demanda por GPUs e aceleradores especializados, como as plataformas da Nvidia, impulsiona modernizações em larga escala. O trade-off aqui é o custo elevado versus o ganho em performance e competitividade. Organizações líderes priorizam ciclos curtos de atualização tecnológica. Planejamento para exascale Segundo a Hyperion, entre 28 e 39 sistemas exascale devem ser instalados globalmente até 2028, com investimentos entre US$ 7 e 10,3 bilhões. Planejar para interoperabilidade com essas arquiteturas é crítico para centros de pesquisa e países que buscam relevância científica. Governança e soberania digital Projetos de IA soberana e data centers nacionais reforçam a importância de manter infraestrutura estratégica sob controle local. Isso garante não apenas performance, mas também independência tecnológica em cenários geopolíticos complexos. Medição de sucesso: métricas e indicadores A efetividade de projetos em HPC e IA pode ser avaliada por métricas como: Capacidade de processamento escalada: ganhos em teraflops ou petaflops disponíveis para cargas críticas. Tempo de treinamento de modelos: redução no ciclo de desenvolvimento de IA. Taxa de utilização da infraestrutura: otimização do CAPEX e OPEX. Impacto científico e industrial: número de descobertas aceleradas por simulações ou IA generativa. Conclusão: perspectivas e próximos passos A análise do mercado global de HPC e IA mostra um cenário em plena aceleração, em que a IA não apenas depende de HPC, mas redefine suas fronteiras. Com CAGR de 47% para servidores HPC focados em IA até 2028, a convergência dessas tecnologias moldará ciência, indústria e governo. Empresas e instituições que estruturarem estratégias híbridas, investirem em modernização acelerada e planejarem para interoperabilidade com sistemas exascale terão vantagens competitivas duradouras. O futuro não é apenas sobre maior poder computacional, mas sobre como alinhá-lo a objetivos estratégicos de inovação e soberania.

Controle de NAS com IA: eficiência empresarial com o QNAP MCP Assistant No cenário empresarial atual, a pressão por eficiência, automação e governança de TI nunca foi tão intensa. O aumento da complexidade nos fluxos de trabalho digitais e o crescimento exponencial do volume de dados obrigam as organizações a buscar soluções mais inteligentes para administração de suas infraestruturas de armazenamento. Nesse contexto, a integração da inteligência artificial diretamente ao NAS corporativo emerge como uma inovação estratégica. O QNAP MCP Assistant representa exatamente essa convergência: a capacidade de operar o NAS com comandos em linguagem natural, transformando um recurso de TI tradicional em uma plataforma responsiva, acessível e altamente eficiente. Empresas de diferentes portes enfrentam dificuldades recorrentes, como a sobrecarga das equipes de TI com tarefas repetitivas, a dependência de conhecimento técnico avançado para configurações simples e o tempo perdido na interpretação de logs ou no gerenciamento de permissões. Ignorar esse problema gera custos ocultos expressivos: lentidão na resposta a incidentes, falhas de governança e perda de competitividade em um mercado cada vez mais orientado por agilidade. Este artigo analisa em profundidade como o controle de NAS com IA via MCP pode redefinir a relação entre tecnologia e operação empresarial, reduzindo riscos e desbloqueando novas formas de produtividade. O problema estratégico no controle tradicional de NAS O gerenciamento de um NAS corporativo historicamente se apoia em duas interfaces principais: a GUI (interface gráfica via navegador) e o CLI (linha de comando). Embora cada uma tenha méritos, ambas impõem barreiras significativas ao uso cotidiano, principalmente em ambientes empresariais dinâmicos. A GUI simplifica tarefas básicas, mas torna fluxos complexos morosos, enquanto o CLI oferece flexibilidade e velocidade, mas exige conhecimento técnico especializado, geralmente restrito a equipes de TI. Esse dilema se traduz em ineficiência organizacional. Supervisores de departamento, por exemplo, podem precisar aguardar suporte da equipe de TI para criar uma nova conta de usuário, mesmo tendo privilégios administrativos. Times de vendas recorrem a colegas do marketing para acessar materiais já armazenados, simplesmente porque a navegação manual na árvore de diretórios é confusa. E em cenários críticos de segurança, como a investigação de acessos suspeitos, a análise manual de logs se torna impraticável diante da urgência. Consequências da inação: riscos e custos ocultos Não enfrentar essas limitações implica em três riscos principais. O primeiro é o custo operacional: profissionais altamente qualificados desperdiçam tempo em tarefas administrativas que poderiam ser automatizadas. O segundo é o risco de governança: atrasos na criação ou ajuste de permissões podem gerar lacunas de compliance, expondo a empresa a vulnerabilidades ou não conformidade regulatória. O terceiro é o risco competitivo: em um mercado que valoriza a agilidade, empresas lentas em responder a mudanças ou incidentes ficam em desvantagem frente a concorrentes mais digitais e responsivos. O resultado é uma sobrecarga para o time de TI e uma frustração crescente para usuários internos. Com isso, práticas informais podem emergir — como compartilhamento de arquivos fora da infraestrutura oficial — criando riscos ainda maiores de segurança e perda de dados. Fundamentos da solução: o MCP como protocolo de contexto O Model Context Protocol (MCP) introduz um novo paradigma. Em vez de obrigar o usuário a dominar comandos ou interfaces específicas, ele permite que o NAS entenda instruções em linguagem natural, mediadas por ferramentas de IA como Claude. A diferença fundamental não está apenas na camada de usabilidade, mas na transformação de um sistema tradicionalmente reativo em um ecossistema proativo, no qual a IA atua como um mordomo digital que compreende contextos e executa fluxos completos. Do ponto de vista técnico, o MCP funciona como um conector de fluxos de trabalho. Ele habilita o diálogo entre a IA e o sistema operacional do NAS, permitindo que comandos simples como “crie uma conta de usuário” ou complexos como “configure uma pasta compartilhada com permissões específicas” sejam traduzidos em operações efetivas. O MCP Assistant, instalado via App Center do QNAP, torna essa integração acessível a qualquer organização com NAS compatível com QTS 5.2 ou QuTS hero h5.2 em diante. Implementação estratégica do MCP Assistant A adoção do MCP Assistant não é apenas uma decisão técnica, mas uma escolha de arquitetura operacional. Sua instalação é semelhante à de outros pacotes QNAP, como o Download Station, mas exige atenção a detalhes como configuração de caminhos absolutos e integração correta com o cliente Claude. Essa etapa inicial garante a comunicação fluida entre o ambiente local e o NAS, evitando falhas de sincronização. Um aspecto crítico é a configuração de credenciais e permissões. O MCP Assistant respeita os níveis de acesso do usuário, garantindo que a IA não execute operações além daquelas autorizadas. Administradores podem inclusive restringir o escopo de atuação à rede local, reforçando o controle de segurança. Outro ponto é a possibilidade de desmarcar o modo somente leitura, habilitando a IA a executar tarefas de escrita, como criação de usuários ou alteração de permissões. Fluxos de trabalho simplificados Com o MCP ativo, a complexidade de múltiplos comandos se reduz a instruções naturais. Exemplos incluem: criar uma pasta compartilhada, atribuir permissões a usuários específicos e, caso necessário, gerar automaticamente novas contas. Outro caso recorrente é a análise de uso de espaço em disco — que pode ser acompanhada de geração automática de gráficos pela própria IA, otimizando a tomada de decisão em tempo real. Segurança operacional A segurança é uma preocupação central em qualquer integração com IA. No caso do MCP, a arquitetura foi projetada para evitar riscos. Funções inexistentes simplesmente não são executadas, bloqueando comandos potencialmente maliciosos. Além disso, todas as ações ficam registradas em logs, permitindo auditoria e rastreabilidade. Essa combinação de restrição funcional e registro detalhado garante que a automação não comprometa a governança. Melhores práticas avançadas de uso Embora seja possível usar a IA para tarefas básicas como renomear arquivos, o verdadeiro valor do MCP Assistant surge em cenários complexos e recorrentes. Um exemplo é a gestão de acessos em grandes equipes, em que permissões precisam ser ajustadas frequentemente. Outra aplicação estratégica é a investigação de incidentes de segurança: em vez
Acronis e Seagate: armazenamento seguro e em conformidade para MSPs No cenário atual de crescimento exponencial de dados e aumento das exigências regulatórias, provedores de serviços gerenciados (MSPs) enfrentam uma pressão sem precedentes para oferecer soluções de armazenamento que conciliem segurança, conformidade e eficiência de custos. A parceria estratégica entre Acronis e Seagate surge como uma resposta a esses desafios, unindo a experiência em segurança cibernética da Acronis à infraestrutura robusta de armazenamento da Seagate, por meio da plataforma Lyve Cloud Object Storage. Este artigo explora em profundidade o impacto dessa aliança no mercado empresarial, analisando os riscos da inação, os fundamentos técnicos da solução Acronis Archival Storage, os benefícios para setores regulamentados e as implicações estratégicas de longo prazo. O objetivo é oferecer uma visão consultiva para líderes de TI e gestores de MSPs que buscam alinhar suas estratégias de armazenamento às crescentes demandas de segurança, conformidade e sustentabilidade financeira. O problema estratégico do armazenamento de longo prazo Empresas modernas lidam com volumes de dados cada vez maiores, impulsionados pela adoção de inteligência artificial, pela digitalização de processos críticos e pela necessidade de retenção de informações para fins legais e regulatórios. A questão não é mais apenas como armazenar esses dados, mas como garantir sua integridade, acessibilidade e conformidade sem que os custos se tornem inviáveis. De acordo com métricas do setor, mais de 60% das organizações já gerenciam volumes superiores a 1 petabyte de dados. Esse dado ilustra não apenas a escala do desafio, mas também o risco associado a modelos de armazenamento tradicionais que não foram projetados para lidar com a magnitude e a criticidade desses ambientes. Provedores de serviços gerenciados, em particular, sentem a pressão de seus clientes em setores como saúde, finanças e serviços públicos, onde a retenção de dados de longo prazo é mandatória. A falha em atender a esses requisitos pode gerar multas regulatórias, perda de credibilidade e exposição a ameaças cibernéticas, especialmente em um cenário onde ataques de ransomware continuam crescendo em sofisticação e frequência. As consequências da inação Ignorar a necessidade de soluções de arquivamento seguras e escaláveis pode ter impactos profundos para empresas e MSPs. Em primeiro lugar, há o risco financeiro associado a multas por não conformidade com normas como ISO 27001 ou SOC 2. Além disso, modelos de armazenamento com custos imprevisíveis podem comprometer o orçamento de TI, especialmente quando cobranças adicionais por tráfego de dados ou acesso à API não são devidamente previstas. No campo da segurança, a ausência de recursos como criptografia em trânsito e em repouso ou a falta de imutabilidade expõe os dados a violações e manipulações maliciosas. Para setores críticos como saúde, em que dados sensíveis de pacientes precisam ser preservados com absoluto rigor, ou para instituições financeiras que lidam com informações altamente reguladas, esses riscos são inaceitáveis. Outro ponto de atenção é a perda de competitividade. Empresas que não adotam práticas robustas de gestão de dados podem perder contratos em licitações que exigem compliance comprovado, além de ficarem vulneráveis a falhas operacionais em auditorias, prejudicando a confiança de clientes e parceiros. Fundamentos técnicos da solução Acronis Archival Storage A oferta resultante da parceria entre Acronis e Seagate, chamada Acronis Archival Storage, foi concebida especificamente para enfrentar os desafios de arquivamento de longo prazo em ambientes de alta regulação. Seu núcleo técnico está na integração do Lyve Cloud Object Storage, da Seagate, com o portfólio de gerenciamento de dados e segurança da Acronis. Criptografia e segurança em múltiplas camadas A solução incorpora criptografia de dados tanto em trânsito quanto em repouso, garantindo que informações sensíveis permaneçam protegidas contra acessos não autorizados em todo o ciclo de vida do armazenamento. Esse recurso, aliado a controles de acesso baseados em funções (RBAC), permite granularidade no gerenciamento de permissões, reduzindo a superfície de ataque. Imutabilidade e prevenção contra ransomware A possibilidade de tornar dados imutáveis representa um diferencial significativo frente a ameaças como ransomware. Ao bloquear alterações em determinados conjuntos de arquivos durante períodos definidos, as organizações asseguram que nem mesmo acessos administrativos maliciosos possam comprometer a integridade das informações arquivadas. Conformidade regulatória integrada Com suporte a padrões internacionais como ISO 27001 e SOC 2, a solução se posiciona como uma ferramenta de apoio direto à governança corporativa. Para empresas em setores altamente regulamentados, essa aderência simplifica processos de auditoria e demonstra o compromisso com a segurança e a conformidade em escala global. Implementação estratégica em ambientes corporativos A adoção do Acronis Archival Storage deve ser vista como parte de uma estratégia de gestão de dados de longo prazo, não apenas como uma solução tecnológica isolada. Para MSPs, o diferencial está na integração transparente com os serviços já oferecidos pela Acronis, permitindo ampliar o portfólio sem complexidade adicional. Do ponto de vista prático, a migração de dados para o Lyve Cloud requer uma análise prévia de volumes, políticas de retenção e classificação de informações. Essa etapa é crítica para evitar que dados ativos sejam confundidos com arquivos de baixo acesso, o que poderia afetar performance e custos. Outro aspecto relevante é o alinhamento com equipes de compliance e segurança da informação, garantindo que políticas internas de governança estejam refletidas na configuração da solução. Isso inclui a definição de papéis, permissões e políticas de retenção que estejam em conformidade com exigências regulatórias. Melhores práticas avançadas para MSPs Para maximizar os benefícios do Acronis Archival Storage, MSPs devem adotar uma abordagem consultiva junto a seus clientes. Isso significa mapear requisitos regulatórios específicos, identificar riscos operacionais e desenhar planos de retenção de dados que equilibrem conformidade, segurança e custos. Entre as práticas avançadas está o uso da imutabilidade em dados de auditoria ou registros médicos, garantindo que esses conjuntos permaneçam inalterados durante o período legal exigido. Outro ponto é a criação de políticas de acesso diferenciadas, em que dados altamente confidenciais sejam acessíveis apenas por grupos restritos com autenticação multifator. Também é recomendável estabelecer métricas de eficiência financeira, monitorando o impacto da eliminação de cobranças por chamadas de API ou tráfego de dados em comparação com modelos de

Servidores de IA Supermicro no INNOVATE 2025: infraestrutura avançada para data center e edge A Supermicro apresentou no evento INNOVATE! EMEA 2025 um portfólio ampliado de servidores de IA, combinando GPUs NVIDIA de última geração, processadores Intel Xeon 6 e soluções modulares para cargas de trabalho críticas em data center e edge. Este artigo aprofunda o contexto, desafios e implicações estratégicas dessa evolução. Introdução: a nova fronteira da infraestrutura de IA O crescimento exponencial da inteligência artificial não é mais um fenômeno restrito a empresas de tecnologia. Hoje, praticamente todos os setores — de telecomunicações a varejo, de saúde a energia — enfrentam a necessidade de processar modelos complexos de IA com rapidez e eficiência. Neste cenário, os servidores de IA Supermicro desempenham um papel estratégico ao fornecer plataformas capazes de sustentar desde treinamento em data centers até inferência na borda. O anúncio da Supermicro no INNOVATE! EMEA 2025, realizado em Madri, evidencia essa transição. A empresa apresentou sistemas otimizados para cargas de trabalho distribuídas que incorporam componentes de ponta, como GPUs NVIDIA RTX Pro™, NVIDIA HGX™ B300, soluções em escala de rack GB300 NVL72 e processadores Intel Xeon 6 SoC. A inclusão de arquiteturas voltadas para edge computing, como o NVIDIA Jetson Orin™ NX e o NVIDIA Grace C1, demonstra uma abordagem integral, capaz de atender tanto o núcleo do data center quanto as fronteiras de rede. As organizações enfrentam hoje um dilema: investir em infraestruturas preparadas para a IA ou correr o risco de perder competitividade. A inação significa lidar com gargalos de rede, custos energéticos crescentes e decisões lentas. O portfólio revelado pela Supermicro busca mitigar esses riscos ao oferecer plataformas modulares, escaláveis e energeticamente eficientes. O problema estratégico: demandas crescentes de IA no data center e na borda A transformação digital acelerada fez com que os volumes de dados crescessem de forma descontrolada. Modelos de IA de larga escala, que antes eram restritos a poucos laboratórios de pesquisa, agora estão sendo aplicados em ambientes corporativos e operacionais. Isso cria dois desafios simultâneos: a necessidade de infraestrutura massiva em data centers e a urgência de capacidades de processamento diretamente na borda da rede. No núcleo do data center, os requisitos envolvem treinamento de modelos cada vez mais complexos, que exigem clusters de GPUs interconectados com alta largura de banda e baixa latência. Já no edge, os cenários são diferentes: dispositivos precisam inferir em tempo real, com restrições severas de energia, espaço e conectividade. A convergência desses dois mundos exige soluções arquitetadas de forma modular, capazes de equilibrar desempenho, eficiência e escalabilidade. Os servidores de IA Supermicro apresentados em Madri respondem a esse problema estratégico. Ao integrar desde sistemas de 1U de curta profundidade até racks completos com suporte a até 10 GPUs, a empresa constrói um ecossistema que permite às organizações implantar IA onde ela gera maior valor. Consequências da inação: riscos de não modernizar a infraestrutura Ignorar a modernização da infraestrutura para IA implica em riscos claros. Primeiramente, há a questão do desempenho. Modelos de IA mal suportados levam a tempos de resposta lentos, que podem inviabilizar aplicações críticas, como análise em tempo real em telecomunicações ou sistemas de recomendação em varejo. Outro fator é o custo energético. Data centers que continuam operando apenas com refrigeração tradicional e servidores de gerações anteriores enfrentam contas de energia crescentes. A Supermicro destacou que muitos de seus novos sistemas podem reduzir em até 40% o consumo energético com soluções de resfriamento líquido — uma diferença que, em escala, representa milhões de dólares anuais. Além disso, há a dimensão competitiva. Empresas que não conseguem treinar e rodar modelos de IA com eficiência ficam para trás em inovação. Isso significa perda de clientes, de relevância de mercado e, em última instância, de receita. A falta de infraestrutura adequada também impacta a capacidade de atender requisitos de compliance e segurança, especialmente em setores regulados. Fundamentos da solução: arquitetura modular da Supermicro A resposta da Supermicro para esses desafios é baseada em seu modelo de Server Building Block Solutions®, que permite construir sistemas sob medida a partir de blocos modulares. Essa abordagem garante que cada cliente possa alinhar sua infraestrutura às necessidades específicas de carga de trabalho, seja em termos de CPU, GPU, armazenamento, rede ou refrigeração. No segmento de GPUs, os novos sistemas incorporam a mais recente geração da NVIDIA, incluindo a plataforma HGX B300 e a solução em escala de rack GB300 NVL72. Essas arquiteturas foram desenvolvidas para cargas de trabalho massivas, com múltiplas GPUs operando em paralelo e otimizadas para treinamento de IA em larga escala. Já no edge, a presença do NVIDIA Jetson Orin NX e do Grace C1 mostra que a empresa não limita sua visão ao data center, mas estende-a para cenários distribuídos. Outro elemento-chave é a integração com processadores Intel Xeon 6 SoC. Esses chips oferecem até 64 núcleos e recursos específicos para telecomunicações, como o vRAN Boost integrado. A combinação com sincronização de tempo GNSS e múltiplas portas de rede de alta velocidade garante que os sistemas estejam prontos para aplicações em redes de alto tráfego. Implementação estratégica: sistemas apresentados no INNOVATE 2025 ARS-111L-FR: IA para telecomunicações O ARS-111L-FR representa a abordagem da Supermicro para ambientes de telecomunicações, onde espaço e eficiência energética são cruciais. Equipado com a CPU NVIDIA Grace C1 e suporte a GPUs de baixo perfil, ele oferece capacidade de IA diretamente em gabinetes de telecom. Isso permite que operadoras integrem serviços inteligentes na borda sem depender do data center central. ARS-E103-JONX: IA compacta para varejo e manufatura O ARS-E103-JONX é um exemplo claro de como a Supermicro traduz necessidades de edge em soluções práticas. Sem ventoinha e alimentado pelo Jetson Orin NX, o sistema oferece até 157 TOPS de desempenho, com conectividade avançada que inclui Ethernet de 10 Gb, 5G e Wi-Fi. Em ambientes de varejo, pode suportar múltiplos pipelines de visão computacional para monitoramento de estoque ou comportamento do consumidor em tempo real. SYS-212D-64C-FN8P: redes de alto tráfego Já o SYS-212D-64C-FN8P foca em locais de rede de alta densidade.

Nvidia Rubin CPX: potência para inferência de IA em contexto massivo A Nvidia anunciou a GPU Rubin CPX, uma inovação projetada para redefinir os limites da inferência de inteligência artificial (IA) em cenários de contexto massivo. Combinando avanços em computação paralela, largura de banda de memória e integração em arquiteturas de data center, a nova geração de GPUs responde a um desafio estratégico: suportar janelas de contexto que deixam para trás os atuais 250.000 tokens e avançam para a escala de milhões. Este artigo analisa em profundidade o anúncio da Nvidia, destacando os problemas estratégicos que levaram à criação do Rubin CPX, as consequências da inação diante da evolução da inferência de IA, os fundamentos técnicos da solução, a implementação em data centers e os impactos estratégicos para empresas que dependem de IA de última geração. Introdução: a mudança de paradigma da IA Nos últimos anos, o debate em torno da inteligência artificial esteve dominado pelo tema do treinamento de modelos cada vez maiores. No entanto, como observou Ian Buck, vice-presidente e gerente geral de hiperescala e HPC da Nvidia, o foco da comunidade está mudando rapidamente para a inferência, ou seja, a execução prática desses modelos em escala empresarial e consumer. Essa mudança redefine não apenas o software, mas também o hardware que sustenta o ecossistema de IA. A inferência apresenta desafios únicos que diferem do treinamento. Enquanto o treinamento busca maximizar throughput em processos intensivos e previsíveis, a inferência exige equilíbrio entre latência, escalabilidade, custo energético e experiência do usuário. Em cargas emergentes como copilotos de programação e geração de vídeo, a pressão recai sobre a capacidade de processar contextos cada vez mais longos sem comprometer a responsividade. Ignorar essa transição representa riscos significativos para data centers e provedores de serviços de IA. Um atraso na adaptação pode significar perda de competitividade, aumento exponencial de custos operacionais e incapacidade de atender a demandas de clientes em mercados que crescem a dois dígitos. O problema estratégico: inferência de IA em escala massiva A complexidade da inferência se manifesta em múltiplos vetores de otimização. Buck destacou que há um constante trade-off entre throughput e experiência do usuário. É possível maximizar a produção de tokens por segundo em um único fluxo, mas isso pode prejudicar a equidade entre múltiplos usuários simultâneos. Além disso, equilibrar eficiência energética e desempenho se tornou um imperativo em fábricas de IA modernas. Outro desafio central é o delta de desempenho entre as fases de inferência. A fase de pré-preenchimento, onde o modelo processa a entrada do usuário e tokens associados, pode explorar paralelismo massivo nas GPUs. Já a fase de geração, que é autorregressiva, exige execução linear, demandando altíssima largura de banda de memória e interconexões NVLink otimizadas. Esse contraste cria gargalos que comprometem a escalabilidade. A solução atual de muitos data centers, baseada em desagregação via cache KV, permite dividir GPUs entre contexto e geração, mas introduz complexidade de sincronização e limitações à medida que os contextos crescem. Consequências da inação diante da evolução da inferência O crescimento exponencial das janelas de contexto pressiona a infraestrutura existente. Modelos atuais conseguem lidar com cerca de 250.000 tokens, mas aplicações emergentes já projetam a necessidade de ultrapassar a barreira de 1 milhão de tokens. Para copilotos de código, isso significa reter em memória mais de 100.000 linhas, enquanto a geração de vídeo amplia a exigência para múltiplos milhões. A ausência de infraestrutura capaz de lidar com esse salto traz riscos claros: Experiência limitada do usuário: respostas truncadas ou inconsistentes em copilotos e assistentes virtuais. Custos crescentes: uso ineficiente de GPUs ao tentar compensar limitações arquiteturais. Perda de mercado: em setores como entretenimento, cujo valor atual de US$ 4 bilhões pode chegar a US$ 40 bilhões na próxima década. Empresas que não se adaptarem rapidamente correm o risco de ficar para trás em um mercado de alto valor, onde a latência e a precisão determinam não apenas competitividade, mas também confiança do cliente. Fundamentos técnicos da solução Rubin CPX A Nvidia respondeu a esse desafio com a GPU Rubin CPX, baseada na arquitetura Rubin e compatível com CUDA. Diferente das gerações anteriores, ela foi otimizada especificamente para cargas de inferência em contexto massivo, com suporte a milhões de tokens. Capacidade computacional O Rubin CPX entrega 30 petaFLOPs de computação NVFP4, estabelecendo uma base sólida para lidar com inferências massivamente paralelas. Esse poder bruto é fundamental para reduzir a lacuna entre as fases de pré-preenchimento e geração. Memória e largura de banda Equipado com 128 GB de memória GDDR7, o Rubin CPX prioriza largura de banda sobre escalabilidade NVLink em cargas de contexto. Essa escolha arquitetural permite lidar com o peso computacional da fase de pré-processamento de maneira mais eficiente. Aceleradores especializados A Nvidia triplicou os núcleos de aceleração de atenção e dobrou os codificadores/decodificadores de vídeo. Esses aprimoramentos respondem diretamente às necessidades de modelos de atenção longos e geração de vídeo em escala, que são pilares de aplicações emergentes. Implementação estratégica em data centers A GPU Rubin CPX não é um elemento isolado, mas parte de uma estratégia integrada de infraestrutura. A Nvidia anunciou sua incorporação nos sistemas Vera Rubin e DGX, ampliando a capacidade desses ambientes. Vera Rubin NVL144 Esse novo sistema oferecerá 8 exaflops de computação de IA, cerca de 7,5 vezes mais que os atuais GB300 NVL72. Ele combina 100 TB de memória rápida e 1,7 petabytes por segundo de largura de banda de memória em um único rack, estabelecendo um novo patamar de densidade computacional. Rack duplo com Rubin CPX Além disso, a Nvidia disponibilizará uma solução de rack duplo que combina a Vera Rubin NVL144 com um “sidecar” de Rubin CPXs, otimizando a distribuição de cargas entre fases de contexto e geração. Melhores práticas para adoção da Rubin CPX Empresas que avaliam a adoção do Rubin CPX devem considerar alguns pontos estratégicos: Balanceamento de cargas: alinhar GPUs dedicadas ao pré-preenchimento e à geração para minimizar latência. Integração com software: explorar o ecossistema CUDA e frameworks de inferência otimizados. Escalabilidade futura: preparar

Supermicro NVIDIA Blackwell Ultra: desempenho em escala para fábricas de IA Introdução A transformação digital em larga escala está redefinindo como as empresas projetam, implementam e escalam suas infraestruturas de Inteligência Artificial (IA). O avanço dos modelos de base, agora compostos por trilhões de parâmetros, exige soluções computacionais de altíssimo desempenho, não apenas em nível de servidor, mas em escala de clusters e data centers inteiros. Neste contexto, a Supermicro anuncia a disponibilidade em massa dos sistemas NVIDIA Blackwell Ultra, incluindo o HGX B300 e o GB300 NVL72. Mais do que novos servidores, essas soluções representam uma abordagem plug-and-play pré-validada, permitindo que organizações implementem fábricas de IA completas com rapidez, eficiência energética e escalabilidade garantida. Ignorar ou adiar a adoção dessa nova geração de infraestrutura pode resultar em riscos competitivos severos, como incapacidade de treinar modelos de IA de última geração, custos operacionais crescentes devido à ineficiência energética e atrasos críticos na disponibilização de novos produtos e serviços baseados em IA. Ao longo deste artigo, exploraremos os desafios estratégicos enfrentados por data centers modernos, as consequências da inação, os fundamentos técnicos do Blackwell Ultra, melhores práticas de implementação e como medir o sucesso de uma adoção bem-sucedida dessa infraestrutura de ponta. O Problema Estratégico: A complexidade das fábricas de IA Construir uma fábrica de IA moderna não é simplesmente adicionar mais servidores ou GPUs. Trata-se de orquestrar uma arquitetura de larga escala que combine computação, rede, armazenamento, resfriamento e software de forma integrada. Modelos com trilhões de parâmetros só são viáveis em infraestruturas com largura de banda extrema e eficiência energética incomparável. Para os líderes empresariais, o desafio vai além da tecnologia: envolve garantir previsibilidade de custos, aderência a cronogramas de implantação e mitigação de riscos operacionais. Uma infraestrutura mal projetada pode comprometer a competitividade de toda a organização. Consequências da Inação A decisão de não modernizar a infraestrutura para padrões como o Supermicro NVIDIA Blackwell Ultra pode gerar impactos diretos: Em primeiro lugar, há o risco de obsolescência tecnológica. Modelos de IA em escala exaflópica exigem densidade computacional que servidores tradicionais não conseguem entregar. Em segundo lugar, os custos de energia e refrigeração aumentam exponencialmente quando se tenta escalar sistemas antigos. A ausência de tecnologias como o resfriamento líquido direto (DLC-2) pode significar gastos até 40% maiores em eletricidade e uso de água, elevando o TCO e comprometendo metas de sustentabilidade. Por fim, empresas que atrasarem a adoção podem perder a janela estratégica de capturar mercados emergentes com soluções baseadas em IA avançada, ficando em desvantagem frente a concorrentes que já operam com fábricas de IA otimizadas. Fundamentos da Solução Blackwell Ultra A arquitetura Blackwell Ultra combina avanços de hardware e software para atender às necessidades de IA em escala. Em nível de sistema, os servidores HGX B300 e racks GB300 NVL72 suportam até 1400 W por GPU, oferecendo desempenho de inferência 50% superior com computação FP4 e 50% mais capacidade de memória HBM3e em relação à geração anterior NVIDIA Blackwell. A densidade computacional é notável: o GB300 NVL72 alcança 1,1 exaFLOPS de desempenho FP4 em escala de rack, enquanto o HGX B300 entrega até 144 petaFLOPS em configurações de 8U refrigeradas a ar ou 4U refrigeradas a líquido. Esses avanços só são possíveis graças à integração do portfólio completo da Supermicro com tecnologias como NVIDIA ConnectX-8 SuperNICs, redes InfiniBand Quantum-X800 e Spectrum-X Ethernet, garantindo até 800 Gb/s de largura de banda. Implementação Estratégica com DCBBS Um diferencial crítico da Supermicro está no Data Center Building Block Solutions® (DCBBS), que entrega não apenas o hardware, mas todo o ecossistema necessário para implantação rápida e confiável em data centers de missão crítica. O DCBBS inclui cabeamento de clusters, integração de energia, gerenciamento térmico e serviços de implantação no local. Esse modelo reduz significativamente o tempo de entrada em operação, eliminando a complexidade de validações isoladas de componentes. Além disso, a tecnologia DLC-2 de resfriamento líquido direto reduz até 40% o consumo de energia, 60% a área física ocupada e 40% o consumo de água, resultando em até 20% de redução no TCO — um ganho estratégico tanto em eficiência operacional quanto em sustentabilidade. Melhores Práticas Avançadas Escalabilidade Progressiva A adoção deve ser planejada em fases, começando por racks GB300 NVL72 isolados e evoluindo para clusters interconectados, garantindo que o investimento acompanhe a maturidade dos casos de uso de IA. Integração de Software A combinação de hardware e software é vital. As soluções Blackwell Ultra já vêm integradas com NVIDIA AI Enterprise, Blueprints e NIM, permitindo que workloads de treinamento, inferência e agentes de IA sejam otimizados desde o primeiro dia. Gestão de Energia e Sustentabilidade Implementar políticas de eficiência energética, alinhadas aos recursos de resfriamento avançado, não apenas reduz custos, mas também melhora o posicionamento corporativo em relação a compromissos ESG. Medição de Sucesso Avaliar a eficácia da implantação de sistemas Supermicro NVIDIA Blackwell Ultra requer métricas claras. Entre as principais estão: Desempenho computacional: FLOPS atingidos em workloads críticos. Eficiência energética: redução percentual no consumo de energia por GPU. Tempo de implantação: dias entre recebimento da solução e início operacional. Escalabilidade: capacidade de expansão modular sem reengenharia da infraestrutura. TCO: redução real de custos totais de propriedade ao longo de 3 a 5 anos. Esses indicadores permitem alinhar a adoção tecnológica com resultados tangíveis de negócio, traduzindo inovação em vantagem competitiva sustentável. Conclusão O lançamento dos sistemas Supermicro NVIDIA Blackwell Ultra marca um divisor de águas para organizações que buscam liderar a corrida da Inteligência Artificial. Com capacidade de entrega em escala exaflópica, eficiência energética sem precedentes e implantação plug-and-play, essas soluções se posicionam como o alicerce das fábricas de IA do futuro. Empresas que investirem agora terão não apenas ganhos de performance, mas também uma vantagem competitiva duradoura em custos operacionais, sustentabilidade e velocidade de inovação. O risco da inação é claro: ficar para trás em um mercado em rápida evolução. O próximo passo para organizações interessadas é avaliar a aderência da arquitetura Blackwell Ultra ao seu roadmap de IA, considerando não apenas os requisitos atuais, mas

Supermicro HGX B200 redefine o desempenho em benchmarks MLPerf 2025 Em abril de 2025, a Supermicro anunciou um marco importante para a indústria de inteligência artificial: seus sistemas baseados no NVIDIA HGX B200 conquistaram a liderança em diversos benchmarks do MLPerf Inference v5.0. Com ganhos de até três vezes na geração de tokens por segundo em comparação com a geração anterior de GPUs, a fabricante consolida sua posição como fornecedora estratégica de soluções de alto desempenho para cargas de trabalho críticas de IA, HPC e nuvem. Introdução A corrida pelo desempenho em inteligência artificial não é apenas uma competição tecnológica. No cenário empresarial atual, ela define a capacidade de organizações inovarem, reduzirem custos e manterem vantagem competitiva em setores cada vez mais dependentes de modelos de IA de larga escala. A Supermicro, em parceria estreita com a NVIDIA, apresentou resultados de benchmark que demonstram não apenas superioridade técnica, mas também impacto direto em eficiência operacional e escalabilidade. Ao superar a geração anterior de sistemas em até três vezes em cenários críticos, como os modelos Llama2-70B e Llama3.1-405B, a empresa envia uma mensagem clara: a infraestrutura de IA empresarial precisa estar preparada para a próxima onda de complexidade e demanda computacional. Neste artigo, analisaremos os resultados obtidos, os fundamentos técnicos das soluções HGX B200 e suas implicações estratégicas para empresas que buscam adotar ou expandir sua infraestrutura de IA. Problema Estratégico Modelos de linguagem e de geração de conteúdo vêm crescendo exponencialmente em tamanho e sofisticação. A cada nova versão, como os LLMs Llama3.1-405B ou arquiteturas Mixture of Experts (MoE), o volume de cálculos e a demanda por largura de banda aumentam de forma significativa. Isso cria um gargalo para organizações que dependem da inferência em tempo real e do treinamento contínuo desses modelos. A infraestrutura tradicional, baseada em gerações anteriores de GPUs, rapidamente se mostra insuficiente. Empresas enfrentam custos crescentes de energia, limitações físicas em datacenters e incapacidade de responder à velocidade exigida pelos negócios. O desafio não está apenas em ter mais GPUs, mas em integrá-las em sistemas capazes de sustentar cargas de trabalho massivas com eficiência térmica, densidade adequada e escalabilidade. Consequências da Inação Ignorar a evolução das arquiteturas de IA significa aceitar desvantagens competitivas profundas. Empresas que permanecem em sistemas defasados correm risco de: Perda de eficiência operacional: modelos que poderiam rodar em tempo real tornam-se lentos, comprometendo aplicações como análise preditiva, automação e atendimento inteligente. Custos crescentes: mais hardware e energia são necessários para tentar compensar a ineficiência, aumentando o TCO. Limitações em inovação: a impossibilidade de executar modelos de última geração limita a adoção de soluções avançadas de IA, como assistentes multimodais ou sistemas de decisão complexos. Riscos de compliance e segurança: atrasos na análise e resposta podem afetar desde a detecção de fraudes até o atendimento a normas regulatórias. Nesse contexto, investir em sistemas como o Supermicro HGX B200 não é apenas uma atualização tecnológica, mas uma decisão estratégica para garantir competitividade e resiliência. Fundamentos da Solução Arquitetura baseada no NVIDIA HGX B200 O núcleo da solução está na utilização da plataforma NVIDIA HGX B200, equipada com oito GPUs Blackwell de alto desempenho. Essa arquitetura permite que sistemas 4U e 10U ofereçam densidade máxima de processamento, mantendo eficiência térmica mesmo sob cargas de trabalho intensas. A Supermicro apresentou duas variantes principais: o sistema SYS-421GE-NBRT-LCC, com refrigeração líquida, e o SYS-A21GE-NBRT, com refrigeração a ar. Ambos demonstraram resultados equivalentes em desempenho nos testes do MLPerf, provando que a eficiência não está limitada apenas a soluções líquidas, mas pode ser atingida também em projetos avançados de refrigeração a ar. Benchmarks MLPerf v5.0 Os benchmarks de inferência da MLCommons são referência global em avaliação de desempenho para sistemas de IA. No caso do HGX B200, os resultados demonstraram: Mixtral 8x7B: até 129.047 tokens/segundo em modo servidor, liderança absoluta no mercado. Llama3.1-405B: mais de 1.500 tokens/segundo em cenários offline e mais de 1.000 em servidores com 8 GPUs. Llama2-70B: desempenho recorde entre fornecedores de nível 1, com mais de 62.000 tokens/s. Stable Diffusion XL: 28,92 consultas/segundo, consolidando a eficiência também em workloads de geração de imagens. Esses resultados, auditados e validados pela MLCommons, destacam não apenas a liderança da Supermicro, mas a reprodutibilidade e a confiabilidade dos sistemas apresentados. Tecnologia de Refrigeração Avançada A refrigeração é um dos pontos mais críticos na operação de sistemas de alta densidade. A Supermicro desenvolveu novas placas frias e uma unidade de distribuição de refrigerante (CDU) de 250 kW, dobrando a capacidade em relação à geração anterior no mesmo espaço 4U. Além disso, o design em escala de rack com coletores verticais de distribuição (CDM) libera espaço valioso. Isso possibilita instalar até 12 sistemas com 96 GPUs Blackwell em apenas 52U, um avanço significativo em densidade computacional sem comprometer a estabilidade térmica. No caso da versão 10U refrigerada a ar, o chassi foi redesenhado para suportar GPUs de 1000 W, garantindo desempenho equivalente ao dos sistemas líquidos. Essa flexibilidade permite que clientes escolham a solução mais adequada à sua infraestrutura de datacenter. Implementação Estratégica Implementar sistemas baseados no HGX B200 exige uma visão estratégica que vá além da simples substituição de hardware. A integração deve considerar desde a preparação da infraestrutura elétrica e de refrigeração até a adequação das aplicações empresariais que serão aceleradas. O modelo de blocos de construção da Supermicro facilita esse processo, permitindo que organizações configurem sistemas sob medida para workloads específicos, seja para inferência em tempo real, seja para treinamento distribuído de larga escala. Outro ponto crítico é a interoperabilidade. Os sistemas HGX B200 foram projetados para funcionar em conjunto com soluções de rede, armazenamento e CPUs já existentes, garantindo que empresas possam evoluir suas arquiteturas de forma progressiva, sem a necessidade de substituição completa. Melhores Práticas Avançadas A experiência prática com sistemas de grande porte revela algumas práticas essenciais para maximizar o valor do investimento: Equilíbrio entre refrigeração e densidade: avaliar cuidadosamente a escolha entre refrigeração líquida e a ar, considerando TCO, manutenção e espaço físico disponível. Escalabilidade modular: adotar racks com múltiplos sistemas HGX B200,

DLC-2 Supermicro: resfriamento líquido estratégico para eficiência em data centers Introdução O crescimento exponencial da inteligência artificial (IA), da computação de alto desempenho (HPC) e da nuvem corporativa está pressionando os data centers globais a revisarem sua arquitetura energética e de resfriamento. A densidade computacional por rack aumentou drasticamente, impulsionada por GPUs de última geração como a NVIDIA Blackwell e CPUs Intel Xeon 6. Nesse cenário, métodos tradicionais de resfriamento a ar começam a atingir limites físicos e econômicos. É nesse contexto que a Supermicro apresenta o DLC-2, sua solução de resfriamento líquido direto projetada para otimizar eficiência, reduzir custos e possibilitar a operação de data centers de IA com densidades sem precedentes. Segundo a empresa, o DLC-2 pode cortar até 40% do consumo de energia e diminuir o TCO em até 20%, transformando não apenas a operação técnica, mas também a estratégia financeira das organizações. A inação frente a essas mudanças acarreta riscos graves: desde custos crescentes com eletricidade e água até perda de competitividade frente a concorrentes que adotarem soluções mais eficientes. Ao longo deste artigo, analisaremos em profundidade o problema estratégico do resfriamento em data centers modernos, as consequências de não agir, os fundamentos técnicos do DLC-2, as práticas de implementação e as métricas para medir o sucesso dessa transição. O problema estratégico do resfriamento em data centers A indústria de data centers vive um dilema: suportar cargas cada vez mais intensivas em computação sem comprometer sustentabilidade e custos. A chegada de arquiteturas como NVIDIA HGX B200, que integra oito GPUs de alto desempenho em apenas 4U de rack, pressiona drasticamente os limites térmicos das instalações. O resfriamento a ar, tradicionalmente utilizado, enfrenta limitações claras. Ventiladores de alta velocidade consomem grande quantidade de energia e geram ruído significativo, frequentemente acima de 80 dB. Além disso, a necessidade de chillers de água gelada implica consumo adicional de energia elétrica e de recursos hídricos, agravando a pegada ambiental e elevando o custo operacional. Do ponto de vista estratégico, organizações que permanecem dependentes de sistemas de resfriamento a ar podem enfrentar gargalos de expansão, já que a infraestrutura não suportará novos racks otimizados para IA. Isso se traduz em barreiras para crescimento de negócios digitais, aumento de OPEX e dificuldade em alinhar operações com metas de ESG. Consequências da inação Ignorar a transição para tecnologias de resfriamento líquido implica não apenas custos mais altos, mas também riscos competitivos severos. A Supermicro estima que até 30% dos novos data centers em breve dependerão de soluções líquidas, criando uma diferença de eficiência entre adotantes e retardatários. Do ponto de vista econômico, continuar investindo em sistemas de refrigeração a ar pode significar até 40% de consumo energético adicional em comparação ao DLC-2. No longo prazo, essa diferença impacta diretamente o TCO, reduzindo margens e comprometendo investimentos em inovação. Além disso, há o risco de indisponibilidade operacional, já que racks de alta densidade podem simplesmente não funcionar em condições térmicas inadequadas. Outro ponto crítico é a sustentabilidade. Governos e investidores estão cada vez mais atentos ao uso de água e energia. Data centers que não reduzem sua pegada ambiental podem enfrentar barreiras regulatórias, perda de incentivos fiscais e danos reputacionais junto a clientes corporativos sensíveis a ESG. Fundamentos da solução DLC-2 O DLC-2 da Supermicro foi concebido como uma resposta arquitetônica aos desafios citados. Trata-se de uma solução de resfriamento líquido direto capaz de capturar até 98% do calor gerado em um rack de servidores. Essa eficiência deriva do uso de placas frias que cobrem não apenas CPUs e GPUs, mas também memória, switches PCIe e reguladores de tensão. O sistema suporta temperaturas de entrada de líquido de até 45 °C, o que elimina a necessidade de chillers de água gelada. Isso se traduz em até 40% de economia no consumo de água, além de reduzir investimentos em compressores e equipamentos auxiliares. Outro benefício direto é a diminuição do número e da velocidade dos ventiladores, levando a níveis de ruído em torno de 50 dB – comparável a uma conversa normal, contra ruídos agressivos de data centers refrigerados a ar. A arquitetura é complementada por uma Unidade de Distribuição de Refrigerante (CDU) com capacidade de remover até 250 kW de calor por rack, além de coletores de distribuição vertical (CDMs), que otimizam a circulação do líquido entre servidores. O resultado é uma solução modular, escalável e adaptada para suportar clusters inteiros de IA e HPC. Implementação estratégica em data centers corporativos A adoção do DLC-2 não deve ser vista apenas como substituição técnica de ventiladores por líquido refrigerante. Trata-se de uma transformação estratégica que impacta desde o design do data center até sua operação diária. Empresas que buscam implementar a solução devem considerar três aspectos fundamentais: planejamento térmico, integração de infraestrutura e governança operacional. Planejamento térmico e arquitetônico O primeiro passo é revisar a arquitetura física do data center. A possibilidade de operar com líquido a 45 °C de entrada significa que a infraestrutura pode ser instalada em regiões com variação climática mais ampla, sem depender de resfriadores caros. Essa flexibilidade reduz CAPEX inicial e amplia o leque de locais viáveis para novas instalações. Integração de servidores e racks O DLC-2 está alinhado a servidores otimizados, como os modelos Supermicro 4U com oito GPUs NVIDIA Blackwell e CPUs Intel Xeon 6. Isso exige que equipes de TI planejem a densidade computacional por rack com cuidado, aproveitando ao máximo o espaço físico liberado pela redução de equipamentos de refrigeração a ar. Governança e operação contínua Outro fator estratégico é o gerenciamento integrado via SuperCloud Composer, que permite orquestrar clusters refrigerados a líquido com visibilidade em nível de data center. Esse recurso garante não apenas eficiência operacional, mas também conformidade com políticas de segurança, auditoria e compliance ambiental. Melhores práticas avançadas A experiência prática mostra que a adoção bem-sucedida do resfriamento líquido depende de um conjunto de melhores práticas. O uso de torres de resfriamento híbridas, por exemplo, combina elementos de torres secas e de água, proporcionando eficiência adicional em locais com grande variação
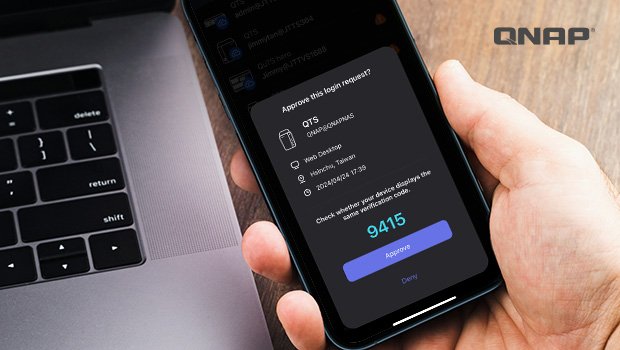
Login sem senha em NAS: mais segurança e eficiência corporativa O modelo tradicional de autenticação baseado em senhas se mostra cada vez mais vulnerável. O login sem senha em NAS emerge como alternativa segura e eficiente para empresas que buscam fortalecer sua estratégia de proteção de dados. Introdução A proteção de dados empresariais depende de mecanismos de autenticação capazes de resistir a ataques cibernéticos sofisticados. Nos últimos anos, a fragilidade do uso de senhas se tornou evidente: senhas fracas, reutilizadas ou mal armazenadas abriram brechas para violações que resultaram em prejuízos financeiros e danos à reputação de organizações de todos os portes. O login sem senha em NAS representa uma mudança de paradigma. Ao substituir credenciais frágeis por autenticação baseada em chaves criptográficas e códigos de verificação únicos, empresas reduzem significativamente a superfície de ataque. A solução não apenas eleva o nível de segurança, como também simplifica a experiência do usuário. Este artigo analisa os fundamentos técnicos, os desafios empresariais relacionados ao modelo de senhas, os riscos da inação, e apresenta como a autenticação sem senha em NAS, com suporte do QNAP Authenticator, pode se integrar a estratégias corporativas de segurança. O problema estratégico das senhas em ambientes corporativos A fragilidade estrutural das senhas Senhas foram, por décadas, o principal mecanismo de controle de acesso a sistemas críticos. No entanto, seu uso massivo trouxe efeitos colaterais graves. É comum encontrar funcionários utilizando combinações previsíveis como “123456” ou datas de aniversário. A pesquisa citada pela QNAP mostra que 30% dos americanos já tiveram dados vazados devido ao uso de senhas fracas, evidenciando a fragilidade estrutural desse modelo. Além da simplicidade, outro problema crítico é a reutilização de senhas. Funcionários tendem a repetir credenciais em diferentes sistemas, criando um efeito cascata: uma única invasão pode comprometer múltiplas plataformas. Essa prática anula qualquer investimento em infraestrutura de segurança se o elo humano permanecer vulnerável. Complexidade operacional e riscos de conformidade Gerenciar múltiplas senhas também impõe desafios operacionais. Em um ambiente empresarial, onde colaboradores precisam acessar dezenas de sistemas, o excesso de credenciais gera frustração, perda de produtividade e aumenta a probabilidade de erros. Do ponto de vista regulatório, a situação é ainda mais crítica. Normas de compliance, como GDPR e LGPD, exigem controles robustos de segurança da informação. Um incidente originado em senhas comprometidas pode levar a multas milionárias e perda de credibilidade no mercado. Consequências da inação A manutenção do modelo de senhas expõe organizações a riscos cumulativos. O custo de um ataque baseado em credenciais roubadas é, hoje, menor do que nunca, dado o mercado negro de senhas disponíveis em vazamentos massivos. Isso significa que, para o invasor, atacar uma empresa por meio de senhas é uma das estratégias mais acessíveis. Entre as principais consequências da inação destacam-se: Maior probabilidade de ataques de força bruta e phishing: técnicas cada vez mais automatizadas exploram falhas humanas. Impacto financeiro direto: custos de recuperação, interrupção de operações e potenciais multas regulatórias. Perda de confiança: parceiros e clientes exigem níveis elevados de segurança. Um incidente mina a reputação corporativa. Portanto, insistir em um modelo baseado em senhas representa não apenas um risco técnico, mas uma ameaça estratégica à competitividade da organização. Fundamentos da solução: login sem senha em NAS Criptografia de chave pública e privada O login sem senha em NAS utiliza princípios avançados de criptografia. O sistema gera um par de chaves: uma pública e outra privada. A chave pública é armazenada no NAS, enquanto a chave privada permanece no dispositivo móvel do usuário. Esse modelo garante que, mesmo em caso de interceptação de dados durante a transmissão, apenas o detentor da chave privada seja capaz de validar o acesso. Trata-se de uma abordagem próxima do conceito de zero trust, onde cada tentativa de acesso exige validação rigorosa de identidade. Assinatura digital como prova de identidade Ao tentar acessar o NAS, o sistema solicita uma verificação de assinatura. O NAS utiliza a chave pública para validar a assinatura gerada com a chave privada do dispositivo. O login só é concluído quando ambas as assinaturas coincidem, criando um processo seguro e à prova de interceptação. Autenticação simplificada com QR Code e código de verificação A experiência do usuário também é otimizada. O login pode ser realizado de duas formas: escaneando um QR Code ou inserindo um código de verificação único através do aplicativo QNAP Authenticator. Essa flexibilidade equilibra praticidade e segurança, reduzindo barreiras de adoção em ambientes corporativos com diferentes perfis de usuários. Implementação estratégica em ambientes corporativos Integração com fluxos de trabalho Para que a autenticação sem senha seja bem-sucedida, é essencial considerar sua integração com processos de negócio existentes. A implementação deve ser gradual, começando por áreas críticas onde o acesso seguro ao NAS é prioritário, como departamentos financeiros e jurídicos. Governança e compliance A adoção deve ser acompanhada por políticas claras de governança. É fundamental documentar os procedimentos de acesso e garantir conformidade com normas regulatórias. A autenticação sem senha fortalece a auditoria de acessos, uma vez que cada tentativa de login gera registros vinculados a chaves criptográficas únicas. Gestão de dispositivos móveis Como a chave privada é armazenada em dispositivos móveis, a gestão desses endpoints se torna estratégica. Empresas precisam adotar práticas de MDM (Mobile Device Management) para assegurar que dispositivos comprometidos possam ser bloqueados rapidamente, evitando riscos de acesso não autorizado. Melhores práticas avançadas Segmentação de usuários e privilégios É recomendável segmentar perfis de usuários de acordo com o nível de criticidade das informações acessadas. Usuários com acesso a dados sensíveis devem obrigatoriamente utilizar autenticação sem senha, enquanto outros podem adotar modelos híbridos. Monitoramento contínuo e auditoria A autenticação sem senha não elimina a necessidade de monitoramento. Sistemas de logging e auditoria devem acompanhar cada tentativa de login, permitindo identificar comportamentos anômalos, como tentativas repetidas de acesso de diferentes dispositivos. Planejamento para escalabilidade Organizações em crescimento devem antecipar como a solução escalará com o aumento do número de usuários e dispositivos. Isso envolve prever capacidade de processamento no NAS e planejar estratégias de balanceamento de carga em ambientes de

Imutabilidade de Dados: Segurança Empresarial Contra Ransomware e Riscos Internos Por que a imutabilidade de dados se tornou pilar de proteção, conformidade e continuidade de negócios em ambientes corporativos modernos. Atualizado com base em conteúdo original QNAP | Contexto: segurança de dados corporativos, WORM, Object Lock, nuvem e on-premises. Introdução Na era digital, dados são ativos centrais do negócio: registros financeiros, informações de clientes e bases analíticas que orientam decisões corporativas. A criticidade desse patrimônio cresceu à medida que ameaças cibernéticas — com destaque para o ransomware — se sofisticaram e ampliaram seu alcance. Nesse cenário, a imutabilidade de dados emerge como tecnologia estratégica para assegurar integridade, resistir a adulterações e viabilizar restauração confiável após incidentes. Além da segurança operacional, a imutabilidade é relevante para conformidade. Regulamentações ao redor do mundo exigem preservação de longo prazo e não adulteração. A capacidade de garantir que dados não sejam alterados ou excluídos após gravação torna-se tanto um mecanismo de proteção quanto um meio para atender requisitos regulatórios. Este artigo aprofunda o conceito de imutabilidade de dados, analisa seu papel na mitigação de ransomware e descreve como soluções da QNAP implementam WORM e Object Lock, abrangendo cenários em nuvem e on-premises. A abordagem conecta implicações técnicas à estratégia empresarial, discute riscos da inação e apresenta fundamentos de implementação com foco em resiliência e conformidade. Visão geral: Conceito de imutabilidade; relevância para negócios e compliance; lições de ataques como o WannaCry (2017); elementos técnicos (WORM, Object Lock, arquitetura em camadas); e como soluções QNAP aplicam esses princípios na prática. Desenvolvimento Problema Estratégico: Integridade de Dados sob Ameaça Em operações modernas, a integridade é condição para continuidade: sem dados íntegros, serviços falham, decisões degradam e obrigações legais se complicam. A superfície de ataque cresceu com digitalização, trabalho distribuído e aumento de volumes de informação, tornando controles puramente preventivos insuficientes. Quando um vetor supera o perímetro, a ausência de uma base imutável expõe o negócio a interrupções e perdas. O ransomware ilustra esse risco: invasores criptografam dados e exigem resgate para liberá-los. Campanhas recentes demonstram que empresas de todos os portes estão no alvo. Mesmo com defesas em rede e rotinas de backup, quando o próprio repositório de cópias é afetado, a recuperação vira uma corrida contra o tempo — e contra a integridade. A imutabilidade endereça o cerne do problema: estabelece que, após gravados, dados não podem ser modificados ou excluídos. Com isso, reduz-se a dependência de medidas apenas preventivas e cria-se um anteparo técnico que resiste a falhas internas, erros operacionais e ataques maliciosos. Cenários críticos de negócio Em setores como financeiro, jurídico e de saúde, registros precisam permanecer íntegros por longos períodos. A necessidade de auditoria, rastreabilidade e preservação torna a imutabilidade não apenas desejável, mas operacionalmente necessária. Nessas áreas, a adulteração pode inviabilizar conformidade e comprometer confiança institucional. Consequências da Inação Sem imutabilidade de dados, violações e erros tendem a propagar-se para camadas de backup e replicação, elevando o tempo de indisponibilidade e a extensão dos danos. Organizações enfrentam riscos de interrupção de serviços, perda de clientes e erosão de reputação — um prejuízo muitas vezes irreversível. Do ponto de vista regulatório, a incapacidade de garantir preservação e não adulteração expõe a penalidades e questionamentos sobre governança. Em ambientes com normas rigorosas, isso amplia custos de auditoria, retrabalho e contingências. Casos históricos, como o ataque WannaCry (2017), evidenciam a gravidade de incidentes que paralisam operações ao criptografar dados críticos. Empresas que mantinham dados imutáveis conseguiram retomar atividades a partir de cópias não adulteradas, sem depender de pagamentos de resgate. Fundamentos da Solução: O que é Imutabilidade de Dados Imutabilidade de dados é a propriedade pela qual, após escrita, a informação torna-se somente leitura — não podendo ser alterada nem excluída durante o período definido. Trata-se de um mecanismo técnico que protege contra adulterações deliberadas, erros acidentais e alterações não autorizadas, mantendo a integridade ao longo do tempo. Dois pilares práticos viabilizam essa propriedade: WORM (Write Once, Read Many) e Object Lock. Ambas as abordagens estabelecem controles no nível do armazenamento para impedir modificações até que condições predefinidas sejam satisfeitas (por exemplo, expiração de um período de retenção). Em implantações maduras, a imutabilidade costuma ser aplicada em uma arquitetura de armazenamento em múltiplas camadas, distribuindo dados por locais físicos ou nuvem, com proteção imutável por camada. Essa redundância melhora resiliência e dificulta que um único evento comprometa todo o acervo. WORM (Write Once, Read Many) O WORM permite que dados sejam gravados uma única vez e, depois, apenas lidos. É amplamente empregado onde a integridade é mandatória: finanças, legislação e saúde, entre outros. Ao impedir modificações e exclusões, o WORM reduz a superfície de risco para adulterações — intencionais ou acidentais — e impede criptografia por ransomware sobre o conteúdo protegido. Object Lock O Object Lock viabiliza a definição de um período de bloqueio por objeto: durante esse intervalo, alterações e exclusões são negadas. Essa flexibilidade é útil quando diferentes tipos de dados exigem prazos de retenção distintos, como em registros clínicos com exigências específicas de guarda. Implementação Estratégica Implementar imutabilidade não é apenas ativar um recurso de armazenamento. É uma decisão de arquitetura que precisa alinhar períodos de retenção, classificação de dados, políticas de acesso e locais de cópia. A combinação de WORM e Object Lock, aplicada a camadas on-premises e em nuvem, cria barreiras complementares que aumentam a capacidade de recuperação. On-premises com NAS e sistema de arquivos Em ambientes locais, um NAS com recursos de imutabilidade consolida proteção próxima das cargas de trabalho. A aplicabilidade inclui uso de WORM, verificação automática e mecanismos de prevenção proativa de danos, além de redundâncias lógicas e otimizações de armazenamento que ajudam a preservar e gerenciar grandes volumes. Nuvem com objetos e retenção Em nuvem, serviços compatíveis com S3 e Object Lock permitem configurar períodos de bloqueio por objeto e aplicar modos de conformidade para impedir alterações dentro da janela definida. A combinação com backup do NAS para a nuvem adiciona um domínio de falha independente. Arquitetura em múltiplas camadas Ao distribuir

IA no varejo: como Supermicro e NVIDIA redefinem eficiência e experiência do cliente No cenário competitivo do varejo moderno, a integração de tecnologias de inteligência artificial deixou de ser uma iniciativa experimental para se tornar um pilar estratégico. A parceria entre Supermicro e NVIDIA, apresentada durante a NRF 2025, ilustra como a infraestrutura de ponta em servidores, armazenamento e computação especializada pode redefinir tanto a operação de loja quanto a jornada do consumidor. Mais do que ferramentas tecnológicas, trata-se de um reposicionamento estrutural da forma como o varejo cria valor, controla custos e constrói resiliência. O problema estratégico do varejo contemporâneo O setor varejista enfrenta um dilema complexo: ao mesmo tempo em que os clientes demandam experiências mais personalizadas, fluidas e digitais, as margens de operação estão cada vez mais pressionadas por custos logísticos, concorrência acirrada e perdas de inventário. Nesse ambiente, decisões baseadas apenas em intuição não sustentam a competitividade. O varejo precisa de tecnologias que combinem inteligência analítica em tempo real com capacidade de escala. A dificuldade histórica está em equilibrar inovação com custo. A personalização de compras, a automação de estoques e a detecção de fraudes exigem grande volume de dados processados com latência mínima. Soluções em nuvem, embora poderosas, muitas vezes não oferecem a velocidade necessária quando a decisão precisa ser tomada no caixa ou no chão de loja. Surge então a necessidade de infraestrutura de edge computing, onde o processamento ocorre próximo da origem dos dados. É nesse ponto que entram as soluções da Supermicro em colaboração com a NVIDIA, trazendo servidores otimizados para cargas de IA, capazes de rodar modelos generativos, analíticos e de inferência em tempo real no ambiente físico da loja. Consequências da inação Ignorar a integração de IA no varejo não representa apenas perder eficiência, mas arriscar a própria sustentabilidade do negócio. Segundo estimativas, apenas a perda de produtos — situações em que mercadorias saem da loja sem pagamento — já causa um prejuízo superior a US$ 100 bilhões anuais nos EUA. Sem tecnologias que apoiem a prevenção, a margem de lucro continua sendo corroída. Além disso, o cliente moderno está acostumado com níveis cada vez mais elevados de personalização em plataformas digitais. Um varejista que não replica essa experiência no ambiente físico passa a ser percebido como defasado, reduzindo fidelização e comprometendo receita recorrente. A consequência prática é a criação de um hiato competitivo: redes que implementam IA conseguem operar com maior eficiência de estoque, menor perda e experiência superior, enquanto as que resistem acumulam custos e sofrem erosão de participação de mercado. Fundamentos da solução Supermicro + NVIDIA A base técnica da proposta está na combinação de hardware especializado da Supermicro com a plataforma de software NVIDIA AI Enterprise, incluindo os microsserviços NVIDIA NIM. Essa arquitetura permite aos varejistas adotar desde aplicações simples de recomendação até soluções avançadas de análise de vídeo e humanos digitais. Os servidores apresentados pela Supermicro cobrem diferentes necessidades de profundidade, escalabilidade e densidade de GPU. Desde modelos compactos para lojas com restrição de espaço até plataformas 3U capazes de suportar até 8 GPUs de largura dupla, como a NVIDIA H100, conectadas via NVLink. Essa flexibilidade é essencial para que o varejo adapte a infraestrutura de acordo com o porte da operação e o perfil de uso. O diferencial estratégico é a execução de modelos diretamente na borda da rede. Isso significa que decisões críticas — como validar um pagamento suspeito ou detectar um erro no caixa — não dependem da latência de ida e volta até a nuvem. O resultado é mais precisão, menor tempo de resposta e experiência fluida para o cliente. Principais sistemas de hardware apresentados A Supermicro apresentou na NRF uma linha robusta de servidores adaptados a diferentes cenários de uso: SYS-112B-FWT: 1U de curta profundidade com processadores Intel Xeon, suporta GPU NVIDIA L40S. AS-1115S-FWTRT: baseado em AMD EPYC, permite flexibilidade na contagem de núcleos e até 1 GPU NVIDIA L40S. SYS-E403-14B: servidor compacto para locais remotos, suporta até 2 GPUs de largura simples ou 1 dupla. SYS-212B-FN2T: 2U de curta profundidade, otimizado para inferência na borda, suporta até 2 GPUs L4. SYS-222HE-TN: 2U com duplo processador Intel Xeon, até 3 GPUs L40S. AS-2115HE-FTNR: 2U AMD EPYC com densidade máxima de até 4 GPUs L40S. SYS-322GA-NR: 3U de alta capacidade, suporta até 8 GPUs H100 ou 19 GPUs de largura única, ideal para salas de controle e grandes operações. Esses modelos não são apenas variações de especificação: cada um atende a um cenário crítico do varejo, seja uma pequena loja de conveniência que precisa de processamento local de vídeo, seja uma rede de hipermercados que exige análise massiva de inventário em tempo real. Implementação estratégica no varejo A introdução de IA não pode ser tratada como simples instalação de servidores. Requer uma estratégia clara que considere desde a seleção dos casos de uso prioritários até a integração com sistemas de gestão existentes. Na NRF, três blueprints de referência da NVIDIA foram demonstrados: 1. Humanos digitais para atendimento A interface “James” exemplifica como avatares virtuais podem atuar como assistentes de compra e atendimento ao cliente. Essa solução combina processamento de linguagem natural com animação realista, oferecendo uma experiência próxima à de interagir com um humano real. A aplicação prática vai além do encantamento: reduz custos com pessoal em funções repetitivas e garante atendimento 24/7 em canais digitais e físicos. 2. Assistentes de compras baseados em IA generativa Com suporte a pesquisa contextual, comparação simultânea de itens e visualização realista de produtos em ambientes do cliente, esse fluxo de trabalho redefine a personalização. Imagine um cliente consultando um sofá e visualizando em tempo real como ele ficaria em sua sala, com renderização física precisa. A fidelização e a taxa de conversão crescem de forma significativa. 3. Busca e sumarização de vídeos para prevenção de perdas A perda de produtos é um dos maiores vilões do varejo. A capacidade de interpretar vídeos em tempo real e identificar erros de registro no caixa traz um impacto imediato no resultado. Mais do que reduzir perdas,

Atualizações de SO, riscos em SSDs e como o NAS ASUSTOR garante a segurança dos dados Nos últimos anos, a confiabilidade do armazenamento digital tornou-se um dos pilares mais críticos da continuidade de negócios. A pressão para atualizar sistemas operacionais em busca de novas funcionalidades, correções de segurança e compatibilidade muitas vezes contrasta com os riscos ocultos que essas atualizações podem trazer. Um exemplo recente envolve relatos de falhas relacionadas a SSDs após grandes atualizações, que resultaram em comportamento anômalo durante operações intensas de gravação. Esses problemas não apenas comprometem a integridade dos dados, como também podem reduzir significativamente a vida útil do hardware. Para as empresas, negligenciar a proteção contra esses riscos significa se expor a perdas financeiras diretas, interrupção de operações críticas e, em última instância, à perda de confiança por parte de clientes e parceiros. Nesse cenário, os backups regulares em um NAS ASUSTOR emergem como um elemento estratégico essencial. Mais do que uma simples cópia de segurança, eles representam uma camada adicional de resiliência operacional diante de falhas inesperadas. Neste artigo, vamos analisar em profundidade como as falhas em SSDs podem ser agravadas por atualizações de SO, quais os riscos reais para empresas que não estruturam políticas de backup adequadas e como as soluções da ASUSTOR — incluindo o ABP no Windows, o Time Machine no macOS e os recentes patches de segurança — garantem proteção robusta contra cenários de falha e vulnerabilidade. O problema estratégico: atualizações de SO e riscos para SSDs O ciclo de vida de qualquer sistema operacional envolve atualizações periódicas. Elas são fundamentais para corrigir falhas, ampliar recursos e oferecer suporte a novos padrões. No entanto, cada atualização carrega consigo a possibilidade de introduzir novos bugs. Um caso recorrente identificado por usuários é a falha que ocorre após transferências de grandes volumes de dados, especialmente em discos com mais de 60% de utilização. O sintoma mais relatado é o desaparecimento temporário do SSD após operações contínuas de gravação que chegam a 50 GB ou mais. Esse comportamento é problemático por duas razões fundamentais. Primeiro, expõe a fragilidade de sistemas que dependem de cargas de escrita intensivas, algo comum em bancos de dados, VMs ou workflows de mídia digital. Segundo, o problema se manifesta de forma intermitente: após reinicializações, o SSD volta a ser detectado, mas o erro retorna quando as mesmas condições de carga são reproduzidas. Para o usuário comum, isso já representa frustração e risco de perda de arquivos. Para empresas, pode significar a interrupção de processos críticos e degradação de performance em serviços essenciais. Ainda mais preocupante é o efeito cumulativo sobre os próprios SSDs. Como as tentativas de gravação são repetidas diversas vezes, o desgaste das células de memória NAND acelera, reduzindo a vida útil efetiva do dispositivo. Ou seja, não estamos apenas diante de um problema de software, mas de uma ameaça concreta ao hardware. Consequências da inação Ignorar esses sinais pode ter consequências severas. Em um cenário corporativo, a corrupção de dados não afeta apenas arquivos isolados, mas pode comprometer sistemas inteiros. Bancos de dados podem se tornar inconsistentes, máquinas virtuais podem falhar ao inicializar e fluxos de trabalho críticos podem ser interrompidos sem aviso. Os custos da inação vão além da substituição de hardware defeituoso. Eles incluem o tempo de indisponibilidade (downtime), perda de produtividade das equipes e até penalidades por descumprimento de SLAs. Empresas de setores regulados, como financeiro e saúde, enfrentam riscos ainda maiores: a perda de dados pode resultar em violações de compliance e sanções legais. Outro impacto importante é a perda de vantagem competitiva. Em mercados digitais, a confiabilidade dos serviços é parte essencial da proposta de valor. Clientes que enfrentam interrupções tendem a migrar para concorrentes, o que agrava o prejuízo em médio e longo prazo. Fundamentos da solução: backups em NAS ASUSTOR A ASUSTOR reforça constantemente a necessidade de desenvolver uma cultura de backup. A premissa é simples: falhas de hardware e bugs de software são inevitáveis, mas a perda de dados não precisa ser. O uso de um NAS ASUSTOR como repositório de backup oferece uma camada adicional de segurança que atua de forma complementar ao próprio sistema operacional. Backups no Windows com ABP O ASUSTOR Backup Plan (ABP) foi projetado para integrar-se de forma nativa ao Windows, permitindo diferentes modalidades de backup: único, agendado ou sincronizado. Essa flexibilidade é vital para empresas que precisam alinhar políticas de backup com a criticidade de seus dados. Por exemplo, bancos de dados transacionais podem exigir backups sincronizados em tempo quase real, enquanto arquivos de projeto podem ser protegidos com agendamentos diários. Um dos grandes diferenciais do ABP é a restauração imediata para o local original. Em caso de corrupção ou falha após uma atualização de SO, o tempo de recuperação (RTO) é drasticamente reduzido, permitindo que operações críticas sejam retomadas rapidamente. Backups no macOS com Time Machine No ecossistema da Apple, a integração é igualmente robusta. O Time Machine, já embutido no macOS, pode direcionar seus backups para um NAS ASUSTOR. Isso garante não apenas a criação de cópias completas do sistema, mas também a capacidade de restaurar o Mac a qualquer ponto anterior no tempo. Um benefício adicional é o suporte a múltiplos dispositivos simultaneamente. Em um escritório com vários Macs, cada máquina pode ter seu próprio espaço independente de backup, garantindo segregação de dados e preservando a privacidade dos usuários. Esse modelo é particularmente relevante em empresas com políticas rígidas de governança de dados. Implementação estratégica Adotar backups em NAS não é apenas uma decisão técnica, mas estratégica. Para usuários Windows, a configuração do ABP deve ser pensada em alinhamento com políticas de retenção de dados, frequência de gravação e criticidade das aplicações. Para usuários macOS, a implementação do Time Machine em rede exige planejamento de capacidade no NAS, garantindo que os volumes dedicados sejam suficientes para múltiplos dispositivos. Outro ponto crítico é a integração com políticas de compliance. Em setores como saúde, finanças e governo, não basta garantir backup — é necessário assegurar criptografia, trilhas de auditoria

Supermicro RTX PRO 6000 Blackwell: infraestrutura de IA empresarial em escala No cenário atual de transformação digital, onde a inteligência artificial deixou de ser apenas um diferencial competitivo para se tornar parte essencial da estratégia corporativa, a infraestrutura tecnológica assume um papel crítico. A Supermicro, em parceria com a NVIDIA, apresenta um portfólio abrangente de servidores otimizados para as novas GPUs NVIDIA RTX PRO 6000 Blackwell Server Edition, reposicionando a forma como empresas podem implantar, escalar e operar suas próprias fábricas de IA.Mais de 20 sistemas já estão disponíveis, abrangendo desde arquiteturas tradicionais em data centers até implementações otimizadas para edge computing. A iniciativa responde a um desafio central das organizações: como acelerar cargas de trabalho de IA — inferência, ajuste fino, desenvolvimento, geração de conteúdo e renderização — sem comprometer desempenho, eficiência energética e custo total de propriedade (TCO). A inação diante dessa evolução pode representar não apenas perda de competitividade, mas também gargalos técnicos e financeiros na jornada de adoção de IA. O problema estratégico da infraestrutura de IA Embora o interesse em IA empresarial cresça de forma exponencial, a maioria das empresas enfrenta um obstáculo fundamental: a infraestrutura de TI tradicional não foi projetada para lidar com a densidade computacional exigida por modelos de linguagem de última geração, algoritmos de inferência em tempo real ou simulações complexas. Isso gera uma lacuna entre a ambição estratégica e a capacidade operacional. Servidores convencionais baseados apenas em CPU se mostram insuficientes para processar simultaneamente múltiplas cargas de trabalho de IA e aplicações gráficas intensivas. Além disso, arquiteturas não otimizadas aumentam o consumo energético, elevam custos de refrigeração e reduzem a longevidade dos investimentos em hardware. O impacto não é apenas técnico: empresas que não conseguem acelerar suas cargas de IA perdem agilidade de mercado, tempo de geração de receita e capacidade de inovação frente à concorrência. Consequências da inação Ignorar a modernização da infraestrutura de IA traz riscos evidentes. O primeiro é o custo oculto da ineficiência: rodar workloads pesados em servidores inadequados exige mais máquinas, mais energia e mais tempo de processamento, o que resulta em aumento do TCO. Além disso, a dependência de arquiteturas defasadas compromete a capacidade de integrar soluções emergentes, como redes de alta velocidade ou pipelines de dados baseados em nuvem híbrida. Outro ponto crítico é a perda de escalabilidade. Organizações que mantêm estruturas inflexíveis enfrentam dificuldades para expandir workloads conforme surgem novas necessidades — por exemplo, ao treinar modelos maiores ou integrar aplicações de IA generativa em escala corporativa. Isso significa menor retorno sobre investimento em inovação e um distanciamento progressivo da fronteira tecnológica que define líderes de mercado. Fundamentos técnicos da solução Supermicro RTX PRO 6000 Blackwell A resposta da Supermicro surge através de um portfólio diversificado de mais de 20 sistemas otimizados para GPUs NVIDIA RTX PRO 6000 Blackwell. Trata-se de uma arquitetura desenhada não apenas para fornecer mais poder computacional, mas para integrar cada elemento da infraestrutura de IA em um ecossistema coeso, escalável e validado pela NVIDIA. Esses sistemas atendem desde grandes data centers até ambientes de borda (edge), com suporte a workloads heterogêneos: inferência em tempo real, ajuste fino de modelos, IA generativa, renderização avançada e desenvolvimento de jogos. A chave está na combinação entre flexibilidade arquitetônica — racks de diferentes dimensões, sistemas multinó como SuperBlade®, soluções compactas otimizadas para Edge — e integração com software NVIDIA AI Enterprise, Spectrum-X e SuperNICs BlueField-3. Essa sinergia full-stack transforma os servidores em blocos de construção para Fábricas de IA empresariais. Arquitetura MGX™ e inferência de IA na borda Um dos destaques é o sistema SYS-212GB-NR, baseado no design de referência NVIDIA MGX™. Com suporte para até 4 GPUs em arquitetura de soquete único, ele possibilita que empresas tragam a potência da RTX PRO Blackwell diretamente para ambientes descentralizados. Isso é especialmente relevante em setores como automação industrial, varejo e análise de negócios em tempo real, onde a latência de rede pode comprometer resultados. Ao implantar GPUs dessa classe no Edge, as organizações reduzem a necessidade de múltiplos servidores para suportar inferência avançada. O resultado é um ganho direto em custo, eficiência energética e simplicidade operacional. Mais do que desempenho, a arquitetura MGX proporciona escalabilidade modular, permitindo que empresas cresçam conforme a demanda sem substituir toda a base de hardware. Flexibilidade com arquiteturas 5U, 4U e 3U O portfólio Supermicro não se limita à borda. Os sistemas 5U oferecem suporte para até 10 GPUs em um único chassi, sendo ideais para cargas intensivas como renderização 3D, simulação científica ou jogos em nuvem. Já os modelos 4U otimizados para MGX permitem até 8 GPUs, balanceando densidade e eficiência térmica. Para data centers compactos, a arquitetura 3U otimizada para Edge suporta até 8 GPUs de largura dupla ou 19 de largura simples. Essa flexibilidade garante que a infraestrutura possa ser moldada de acordo com os requisitos específicos de cada empresa, sem comprometer desempenho ou eficiência. SuperBlade® e GrandTwin®: densidade em escala Quando o desafio é maximizar densidade em ambientes corporativos, as soluções multinó da Supermicro se destacam. O SuperBlade®, por exemplo, permite até 40 GPUs em um gabinete 8U e até 120 GPUs por rack, com foco em eficiência energética. Essa abordagem viabiliza workloads críticos como EDA, HPC e IA em larga escala. Já o GrandTwin® oferece flexibilidade para cargas mistas, permitindo que cada nó seja configurado de acordo com a necessidade. Isso garante maior aproveitamento do hardware e otimização de custos, algo essencial em ambientes corporativos com múltiplas demandas simultâneas. Implementação estratégica em fábricas de IA empresariais Mais do que hardware, a proposta da Supermicro com a RTX PRO 6000 Blackwell é acelerar a construção de Fábricas de IA — ambientes integrados que reúnem processamento, armazenamento, rede e software para viabilizar todo o ciclo de vida de modelos de IA. A certificação pela NVIDIA garante interoperabilidade com Spectrum-X, armazenamento certificado e NVIDIA AI Enterprise. Na prática, isso significa que empresas podem adotar um modelo full-stack já validado, reduzindo riscos de incompatibilidade e acelerando o tempo de implantação. Além disso, a abordagem Building

Supermicro expande portfólio NVIDIA Blackwell para fábricas de IA empresariais No cenário atual de transformação digital, a inteligência artificial (IA) deixou de ser apenas um diferencial competitivo e se tornou elemento central das estratégias corporativas. A capacidade de treinar, implantar e operar modelos avançados exige não apenas algoritmos sofisticados, mas também infraestrutura de alto desempenho e escalabilidade comprovada. É neste contexto que a Supermicro, em colaboração estreita com a NVIDIA, apresenta um portfólio sem precedentes de soluções projetadas para a arquitetura NVIDIA Blackwell, direcionadas especificamente para atender à crescente demanda por fábricas de IA empresariais no mercado europeu. O anúncio de mais de 30 soluções distintas, incluindo plataformas baseadas no NVIDIA HGX B200, no GB200 NVL72 e na RTX PRO 6000 Blackwell Server Edition, reforça não apenas a posição de liderança da Supermicro no setor, mas também estabelece um novo patamar de eficiência energética, confiabilidade operacional e tempo de entrada em produção. Mais do que servidores, trata-se de um ecossistema de componentes certificados pela NVIDIA que acelera a transição de data centers convencionais para verdadeiras fábricas de IA. Problema estratégico: a lacuna entre ambição e infraestrutura As organizações europeias estão diante de um dilema crítico. Por um lado, a pressão para adotar IA em escala cresce em ritmo acelerado, impulsionada por casos de uso que vão da análise preditiva ao suporte automatizado em tempo real. Por outro, a infraestrutura tradicional de TI encontra severas limitações quando confrontada com modelos cada vez mais complexos e com volumes massivos de dados. O desafio não está apenas em adquirir hardware potente, mas em integrar de forma orquestrada GPUs, redes de alta velocidade, sistemas de resfriamento e software corporativo. Muitas empresas descobrem que a complexidade de implantação pode transformar um projeto estratégico em um gargalo operacional, consumindo meses ou anos até entrar em operação. Essa lacuna entre ambição e capacidade efetiva ameaça diretamente a competitividade. Consequências da inação: riscos e custos ocultos Ignorar essa realidade traz consequências severas. Empresas que adiam a modernização de sua infraestrutura de IA correm o risco de perder vantagem competitiva frente a concorrentes que já operam com arquiteturas de última geração. Os custos da inação se manifestam em múltiplas dimensões: Perda de agilidade Sem acesso a recursos acelerados, projetos de IA levam meses para atingir resultados, enquanto concorrentes conseguem ciclos de iteração em semanas. A lentidão no desenvolvimento impacta diretamente a inovação. Excesso de custos operacionais Data centers que dependem exclusivamente de refrigeração a ar convencional consomem significativamente mais energia e não conseguem escalar de maneira eficiente. Isso eleva o custo total de propriedade e gera barreiras para sustentar cargas de trabalho contínuas. Exposição a riscos tecnológicos Empresas presas a infraestruturas legadas enfrentam maior vulnerabilidade frente a rupturas tecnológicas. Quando novos modelos exigem padrões mais avançados de rede ou GPUs de próxima geração, a falta de compatibilidade torna inviável o aproveitamento imediato. Fundamentos da solução: arquitetura NVIDIA Blackwell integrada A resposta estratégica da Supermicro é construir sobre a arquitetura NVIDIA Blackwell uma oferta integrada, validada e escalável. O portfólio inclui desde servidores baseados no HGX B200 até plataformas completas com GB200 NVL72 refrigerado a líquido e servidores equipados com RTX PRO 6000 Blackwell Server Edition. A diversidade de soluções não é um detalhe estético, mas uma necessidade diante da heterogeneidade dos ambientes corporativos. O princípio central dessa abordagem é a interoperabilidade. Todos os sistemas são certificados pela NVIDIA e projetados para funcionar de forma nativa com a Enterprise AI Factory, que integra hardware, rede Ethernet NVIDIA Spectrum-X, armazenamento certificado e o software NVIDIA AI Enterprise. Isso garante que a infraestrutura de IA corporativa não seja apenas poderosa, mas também consistente e de fácil manutenção. Implementação estratégica: do projeto à operação Um dos maiores obstáculos históricos em implantações de IA empresarial é o tempo de entrada em produção. Tradicionalmente, a integração de servidores, rede e software pode levar de 12 a 18 meses. A Supermicro propõe um salto quântico: com sua abordagem de Building Block Solutions e integração com o SuperCloud Composer®, esse prazo pode ser reduzido para apenas três meses. Esse encurtamento de prazos não se dá por mágica, mas pela combinação de três fatores: (1) sistemas pré-validados pela NVIDIA, (2) plantas de data center flexíveis, que já contemplam resfriamento líquido via DLC-2 e compatibilidade com racks de 250 kW, e (3) serviços profissionais de implantação no local, eliminando a dependência de múltiplos fornecedores. O resultado é a possibilidade de iniciar cargas de trabalho de IA imediatamente após a entrega da infraestrutura. Melhores práticas avançadas: eficiência térmica e escalabilidade Entre os destaques técnicos, o DLC-2 merece atenção especial. Essa tecnologia de refrigeração líquida permite remover até 250 kW de calor por rack, assegurando que mesmo as cargas de trabalho mais intensivas possam ser sustentadas sem degradação térmica. Isso não apenas reduz os custos de energia, mas também prolonga a vida útil dos componentes críticos. Outro ponto-chave é a escalabilidade planejada. O portfólio atual já contempla compatibilidade com futuras gerações de hardware, como o NVIDIA GB300 NVL72 e o HGX B300. Essa visão de longo prazo garante que os investimentos realizados hoje não se tornem obsoletos em poucos anos, protegendo o capital e assegurando continuidade operacional. Medição de sucesso: indicadores estratégicos Medir a eficácia da implantação de uma fábrica de IA não se resume a avaliar benchmarks de GPU. A perspectiva empresarial exige métricas que conectem desempenho técnico a impacto de negócio. Entre os indicadores mais relevantes estão: Tempo de entrada em produção Reduzir de 12-18 meses para 3 meses representa não apenas eficiência técnica, mas uma aceleração estratégica do retorno sobre investimento. Eficiência energética A capacidade de operar cargas contínuas com menor consumo impacta diretamente o TCO (Total Cost of Ownership) e melhora a sustentabilidade corporativa. Escalabilidade sem interrupção A adoção imediata de novas gerações de GPUs e arquiteturas sem necessidade de reconfiguração estrutural é um diferencial competitivo crítico. Conclusão: o futuro das fábricas de IA na Europa A expansão do portfólio da Supermicro para a arquitetura NVIDIA Blackwell não é apenas uma evolução tecnológica, mas um

Supermicro H14 com AMD Instinct MI350: Potência máxima em IA e eficiência energética Introdução O avanço da inteligência artificial (IA) corporativa está diretamente ligado à evolução das arquiteturas de hardware que a suportam. Em um cenário onde modelos de linguagem, análise preditiva, inferência em tempo real e simulações científicas exigem processamento maciço, a eficiência energética e a escalabilidade se tornaram tão críticas quanto a própria capacidade de cálculo. Nesse contexto, a Supermicro, combinando sua expertise em soluções de data center e HPC, apresenta a geração H14 de servidores GPU equipados com as novas GPUs AMD Instinct™ MI350 Series, baseadas na arquitetura AMD CDNA™ de 4ª geração. Essas soluções foram projetadas para ambientes empresariais de missão crítica, capazes de lidar com treinamento e inferência de grandes modelos de IA, mantendo baixo custo total de propriedade (TCO) e alta densidade computacional. A combinação de GPUs AMD Instinct MI350, CPUs AMD EPYC™ 9005 e opções avançadas de resfriamento a líquido ou a ar entrega não apenas desempenho extremo, mas também flexibilidade de implementação para diferentes perfis de data center. Este artigo apresenta uma análise detalhada da abordagem técnica e estratégica da Supermicro com a linha H14, explorando os desafios que ela resolve, seus fundamentos de arquitetura, melhores práticas de adoção e métricas para avaliar seu sucesso em cenários reais. O problema estratégico Empresas que atuam na fronteira da IA enfrentam uma barreira dupla: por um lado, a demanda por poder computacional cresce exponencialmente; por outro, as limitações físicas e energéticas dos data centers impõem restrições severas. O aumento do tamanho dos modelos e o volume de dados a serem processados pressiona não apenas a CPU, mas sobretudo a GPU e a memória de alta largura de banda. Sem infraestrutura adequada, organizações acabam comprometendo a velocidade de treinamento, limitando a complexidade dos modelos ou elevando drasticamente o consumo energético — um fator que impacta tanto o orçamento quanto as metas ambientais de ESG. A ausência de soluções que conciliem alto desempenho com eficiência energética representa uma perda competitiva significativa. Consequências da inação Ignorar a modernização da infraestrutura de IA significa aceitar tempos de processamento mais longos, custos operacionais mais altos e menor capacidade de resposta a demandas de negócio. Modelos que poderiam ser treinados em dias passam a levar semanas, comprometendo a agilidade na entrega de novos serviços baseados em IA. Além disso, sem sistemas projetados para lidar com alta densidade térmica, o risco de falhas e degradação prematura de hardware aumenta substancialmente. No cenário competitivo atual, a latência na entrega de soluções de IA não é apenas um problema técnico — é uma ameaça direta à relevância no mercado. Fundamentos da solução A resposta da Supermicro é uma arquitetura modular e otimizada para cargas de trabalho intensivas em IA, suportada pelas GPUs AMD Instinct MI350 Series. Baseada na arquitetura AMD CDNA™ de 4ª geração, essa linha oferece até 288 GB de memória HBM3e por GPU, totalizando impressionantes 2,304 TB em servidores de 8 GPUs. Essa configuração não apenas amplia a capacidade de memória em 1,5x em relação à geração anterior, como também proporciona largura de banda de 8 TB/s, essencial para alimentar modelos de IA com volumes massivos de dados. O salto de desempenho é igualmente significativo: até 1,8x petaflops de FP16/FP8 em relação ao modelo MI325X, com novos formatos FP6 e FP4 que aumentam a eficiência em inferência e treinamento. Essa potência é combinada a CPUs AMD EPYC 9005, garantindo equilíbrio entre processamento paralelo massivo e tarefas de coordenação e pré-processamento de dados. Eficiência energética integrada Os sistemas H14 oferecem opções de resfriamento a líquido (4U) e a ar (8U). O design de Resfriamento Líquido Direto (DLC) aprimorado da Supermicro pode reduzir o consumo de energia em até 40%, resfriando não apenas as GPUs, mas múltiplos componentes críticos, o que maximiza o desempenho por rack e viabiliza operações em alta densidade. Interoperabilidade e padrões abertos A adoção do Módulo Acelerador OCP (OAM), um padrão aberto da indústria, garante que as soluções sejam compatíveis com múltiplas arquiteturas e simplifica a integração em infraestruturas OEM já existentes, reduzindo barreiras para atualização de data centers. Implementação estratégica Para adoção efetiva das soluções H14 com AMD MI350, as empresas devem alinhar a implementação ao perfil de carga de trabalho. Treinamento de modelos de grande escala se beneficia mais de configurações líquidas de alta densidade, enquanto cargas de inferência distribuída podem operar eficientemente em versões refrigeradas a ar. A estratégia de implementação deve considerar: Topologia de rede interna: maximizar a largura de banda entre GPUs e nós para evitar gargalos na troca de parâmetros durante o treinamento. Planejamento térmico: avaliar a infraestrutura existente para suportar DLC ou identificar melhorias necessárias para refrigeração eficiente. Balanceamento de custo e desempenho: identificar o ponto ótimo entre investimento inicial e ganhos em tempo de processamento, considerando o TCO ao longo do ciclo de vida. Melhores práticas avançadas Dimensionamento baseado em métricas reais Antes da aquisição, realizar benchmarks internos com modelos representativos das cargas de trabalho reais garante que a configuração seja dimensionada corretamente. Integração com ecossistema AMD ROCm™ As GPUs AMD MI350 são suportadas pela plataforma ROCm, que oferece bibliotecas e ferramentas otimizadas para IA e HPC. Integrar esses recursos ao pipeline de desenvolvimento acelera a entrega de soluções. Governança e compliance Com maior capacidade de processamento e armazenamento, cresce também a responsabilidade sobre segurança de dados. É essencial implementar criptografia em trânsito e em repouso, além de controles de acesso rigorosos, especialmente em projetos que envolvem dados sensíveis. Medição de sucesso A avaliação do sucesso da implementação deve ir além de benchmarks sintéticos. Indicadores recomendados incluem: Redução no tempo de treinamento de modelos-chave. Eficiência energética medida em operações reais (watts por token processado). Escalabilidade do ambiente sem perda de desempenho linear. Taxa de utilização efetiva das GPUs e memória HBM3e. Conclusão As soluções Supermicro H14 com GPUs AMD Instinct MI350 representam um avanço significativo para empresas que buscam impulsionar sua capacidade de IA com equilíbrio entre potência, eficiência e flexibilidade. Ao combinar arquitetura de última geração, opções avançadas

Servidor Supermicro BigTwin com Certificação Intel para Resfriamento por Imersão No cenário atual de data centers voltados para inteligência artificial (IA), computação de alta performance (HPC) e cargas de trabalho críticas, a gestão térmica eficiente é um desafio estratégico. O aumento constante de densidade de processamento e consumo de energia dos servidores tradicionais torna indispensável a adoção de soluções inovadoras de resfriamento. Servidores de alto desempenho, como os da linha Supermicro BigTwin, precisam equilibrar poder computacional extremo com sustentabilidade operacional e eficiência energética. O resfriamento inadequado não apenas compromete a confiabilidade dos sistemas, mas também eleva o custo operacional e o impacto ambiental de toda a infraestrutura. Data centers que ignoram essas necessidades enfrentam PUE (Power Usage Effectiveness) elevado, maior risco de falhas e limitação de expansão em ambientes densos. Este artigo analisa detalhadamente a solução de resfriamento por imersão certificada pela Intel para o servidor Supermicro BigTwin, explorando fundamentos técnicos, implementação estratégica, melhores práticas e métricas de sucesso, oferecendo uma visão completa para líderes de TI e gestores de data center. Problema Estratégico: Gestão Térmica em Data Centers de Alta Densidade Data centers modernos enfrentam pressões para aumentar o desempenho computacional sem comprometer a eficiência energética. Servidores tradicionais, resfriados a ar, geram desafios críticos: dissipação insuficiente de calor, necessidade de sistemas CRAC/CRAH complexos e limitações de densidade de rack. Tais restrições impactam diretamente a capacidade de expansão e o TCO (Total Cost of Ownership). Aplicações de IA e HPC exigem processadores de alta potência, como os Intel Xeon de 5ª geração, que geram calor intenso. Sem soluções avançadas de resfriamento, os operadores enfrentam risco de throttling, falhas de hardware e aumento no consumo de energia global do data center. Consequências da Inação Manter servidores de alta densidade sem soluções adequadas de resfriamento implica em custos operacionais elevados, maior risco de downtime e comprometimento da performance. PUE elevado, acima de 1,5, significa desperdício de energia significativa, além de impacto ambiental. Além disso, limita a escalabilidade das operações e impede a adoção plena de tecnologias de IA e HPC. Fundamentos da Solução: Resfriamento por Imersão A Supermicro, em parceria com a Intel e seguindo diretrizes do Open Compute Project (OCP), desenvolveu e certificou o BigTwin para resfriamento por imersão. Esta tecnologia submerge os componentes do servidor em fluido dielétrico termicamente condutor, eliminando ventoinhas internas e sistemas tradicionais de ar condicionado. O calor é dissipado de forma direta e eficiente, permitindo PUE próximos a 1,05. O design do BigTwin SYS-221BT-HNTR integra quatro nós hot-pluggable em 2U, com suporte para processadores Intel Xeon 4ª/5ª geração, até 4 TB de memória DDR5-5600 e conectividade PCIe 5.0. Fontes de alimentação redundantes de 3000 W com eficiência nível titânio complementam a arquitetura, permitindo operação confiável mesmo em condições de alta densidade térmica. Compatibilidade e Padronização OCP O servidor atende rigorosos critérios de compatibilidade OCP para materiais e fluidos de imersão, garantindo interoperabilidade e padronização em todo o setor. Essa certificação permite integração com tanques e soluções de resfriamento por imersão de diferentes fornecedores, simplificando a implementação e manutenção em data centers corporativos. Implementação Estratégica A implementação de resfriamento por imersão exige avaliação detalhada de infraestrutura, incluindo tanque de imersão, líquido dielétrico, monitoramento térmico e protocolos de manutenção. A parceria Supermicro + Intel fornece soluções testadas e certificadas, reduzindo riscos de falha de hardware, instabilidade ou incompatibilidade com software e sistemas existentes. Além disso, servidores pré-configurados para operação em imersão simplificam a implantação e reduzem o esforço de integração, minimizando downtime e mantendo desempenho máximo em workloads críticos de IA/HPC. Melhores Práticas Avançadas Para maximizar eficiência e confiabilidade, recomenda-se: Monitoramento contínuo da temperatura e densidade de fluxo do fluido dielétrico; Planejamento de redundância de energia e rede considerando PUE otimizado; Utilização de componentes hot-pluggable certificados para imersão; Atualização e manutenção dentro de padrões OCP, garantindo compatibilidade de longo prazo. Essas práticas garantem que o servidor BigTwin opere com máximo desempenho, eficiência energética e segurança operacional, permitindo escalabilidade sem comprometer o TCO ou confiabilidade. Medição de Sucesso Métricas críticas para avaliar a eficácia incluem: PUE atingido pelo data center (valores próximos a 1,05 indicam eficiência ótima); Redução de consumo energético de sistemas CRAC/CRAH; Performance sustentada de cargas de IA/HPC sem throttling; Taxa de falhas e manutenção preventiva reduzida. O uso da certificação Intel e diretrizes OCP permite indicadores confiáveis de desempenho, alinhando operação de data centers a metas estratégicas de eficiência e sustentabilidade. A certificação de resfriamento por imersão do servidor Supermicro BigTwin representa um marco estratégico em eficiência de data centers, especialmente para aplicações de IA e HPC de alta densidade. Ao integrar arquitetura multinó de alto desempenho, fluido dielétrico eficiente e padrões OCP, o BigTwin oferece operação confiável, densidade máxima e PUE otimizado. Organizações que adotam esta solução podem reduzir custos energéticos, melhorar desempenho operacional e atingir objetivos de sustentabilidade, ao mesmo tempo em que aumentam a escalabilidade do data center. O futuro do gerenciamento térmico em data centers passa por soluções de resfriamento por imersão, com potencial de transformar a eficiência energética e permitir cargas de trabalho cada vez mais exigentes em IA e HPC. Para líderes de TI, o próximo passo é avaliar a integração de servidores certificados para imersão em seus ambientes, alinhando operação com padrões OCP, certificação Intel e melhores práticas de eficiência energética.


















